Scalability and Performance Planning
We evaluate and examine your current architecture, traffic patterns, and system behaviour under load so you gain complete clarity on where bottlenecks are forming. This gives a clear picture of what capacity constraints are limiting your growth, and the most effective path to building infrastructure that performs reliably at any scale.

100+Reviews
1000+Projects Delivered
Build Systems That Grow With Your Ambitions, Not Against Them
550+ Engagements Since 2006 — Trusted By
Most product teams never discover their scalability ceiling until a traffic spike, a product launch, or a viral moment exposes it in front of their most important users. Our Scalability & Performance Assessment identifies every architectural constraint, capacity bottleneck, and performance risk before your system encounters the load that reveals them.
Your infrastructure becomes deliberately designed for growth, degradation events stop catching your team off guard, and the architecture you operate genuinely supports the business trajectory you are pursuing. You leave with a concrete, prioritized execution plan your engineers can begin implementing without delay.
CUSTOMER STORIES
Client Results and Success
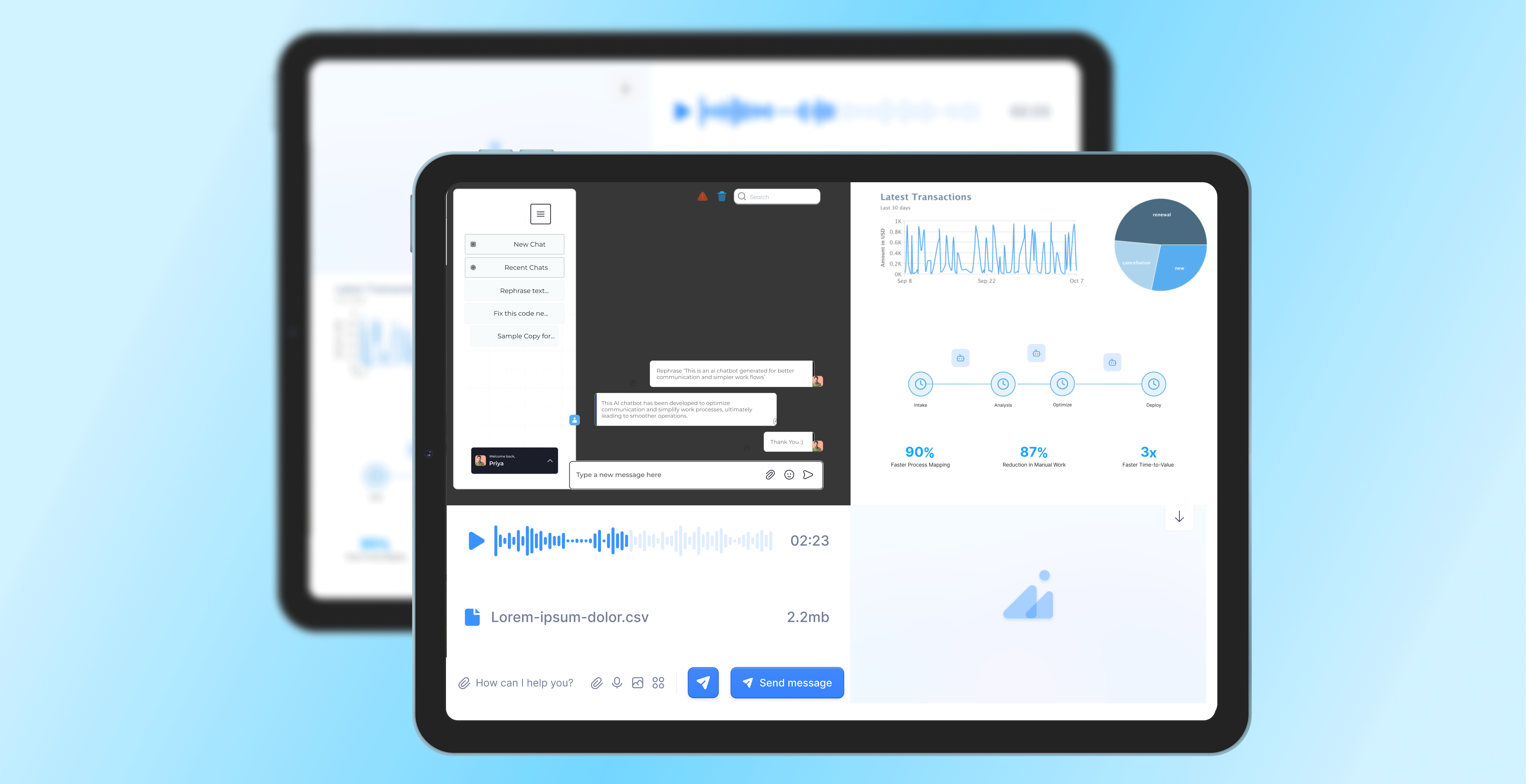
WHAT WE DO
Our Scalability Assessment Examines Three Foundational Dimensions
Every engagement begins with a rigorous, evidence-based evaluation spanning three critical aspects of your system's ability to perform under pressure: your architectural scalability, your application-level performance characteristics, and your operational readiness to manage growth without accumulating unsustainable complexity.
We never base scalability recommendations on theoretical architecture reviews conducted in isolation from real system behaviour. Our AI-empowered engineers examine your actual traffic patterns, your genuine load test results, your database query profiles, and your production incident history. The outcome is a performance strategy grounded in how your system actually behaves — not how it was designed to behave on paper.
Architectural Scalability Review
Application Performance Analysis
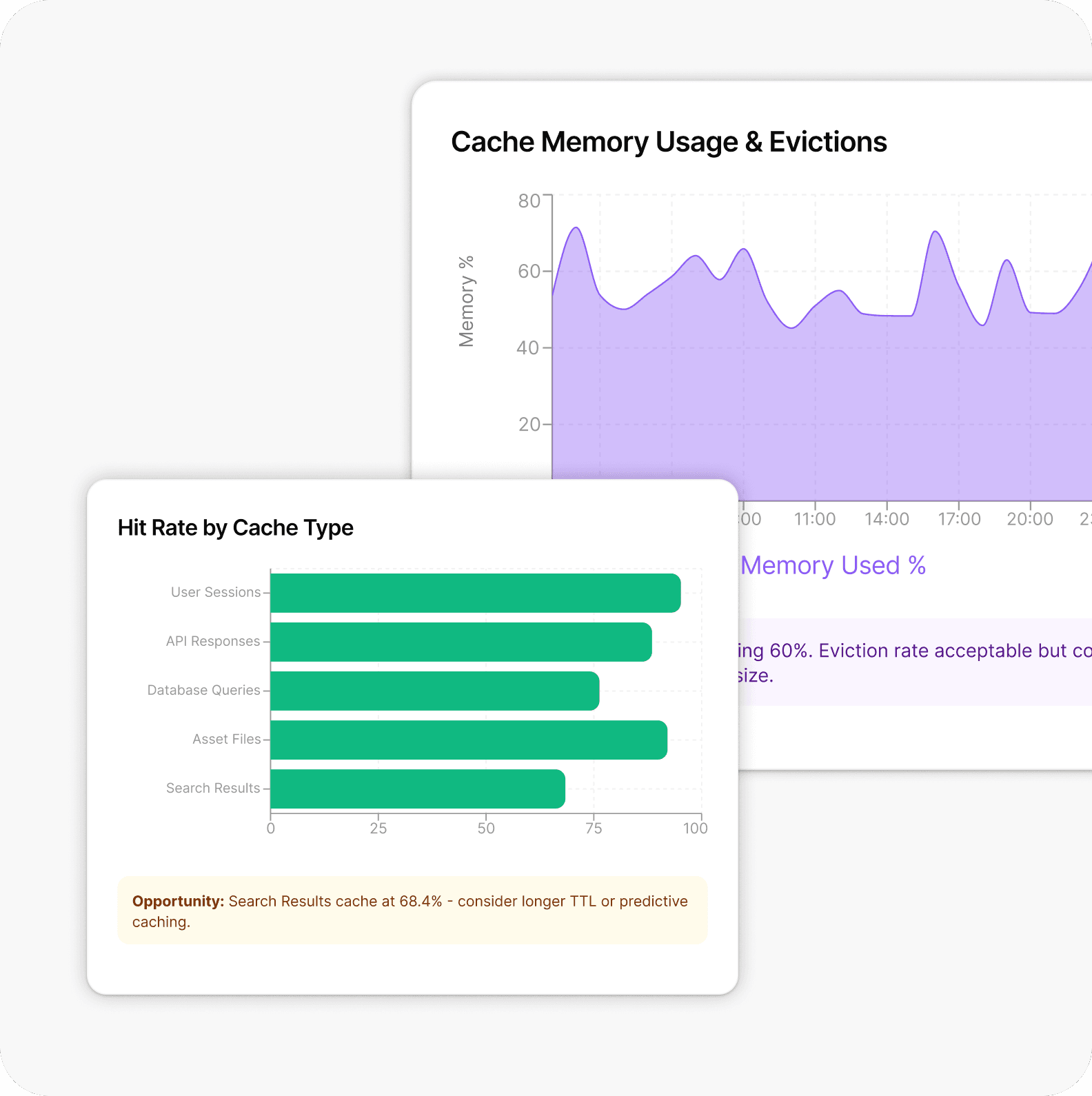
Operational Scalability Readiness Review
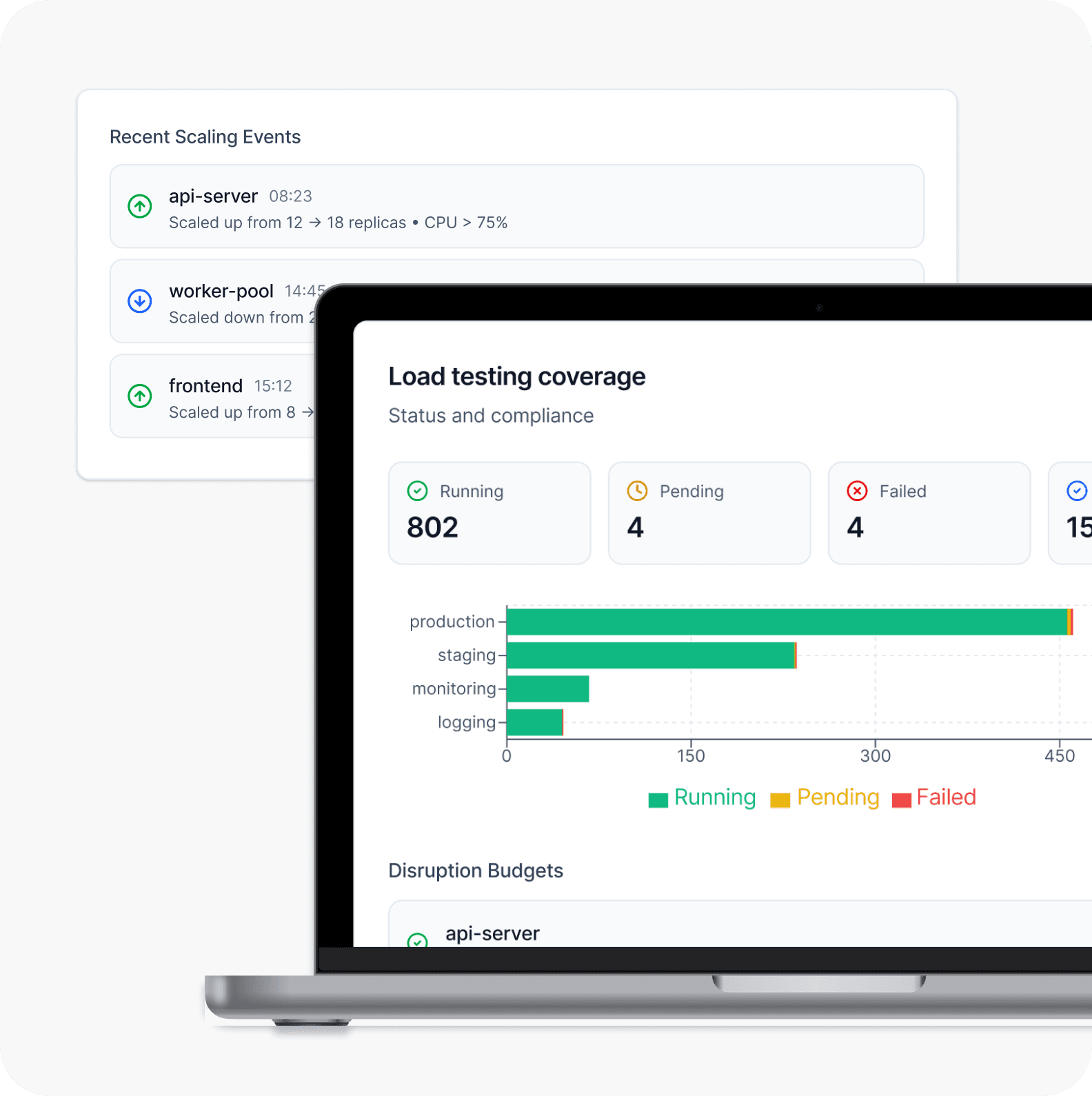
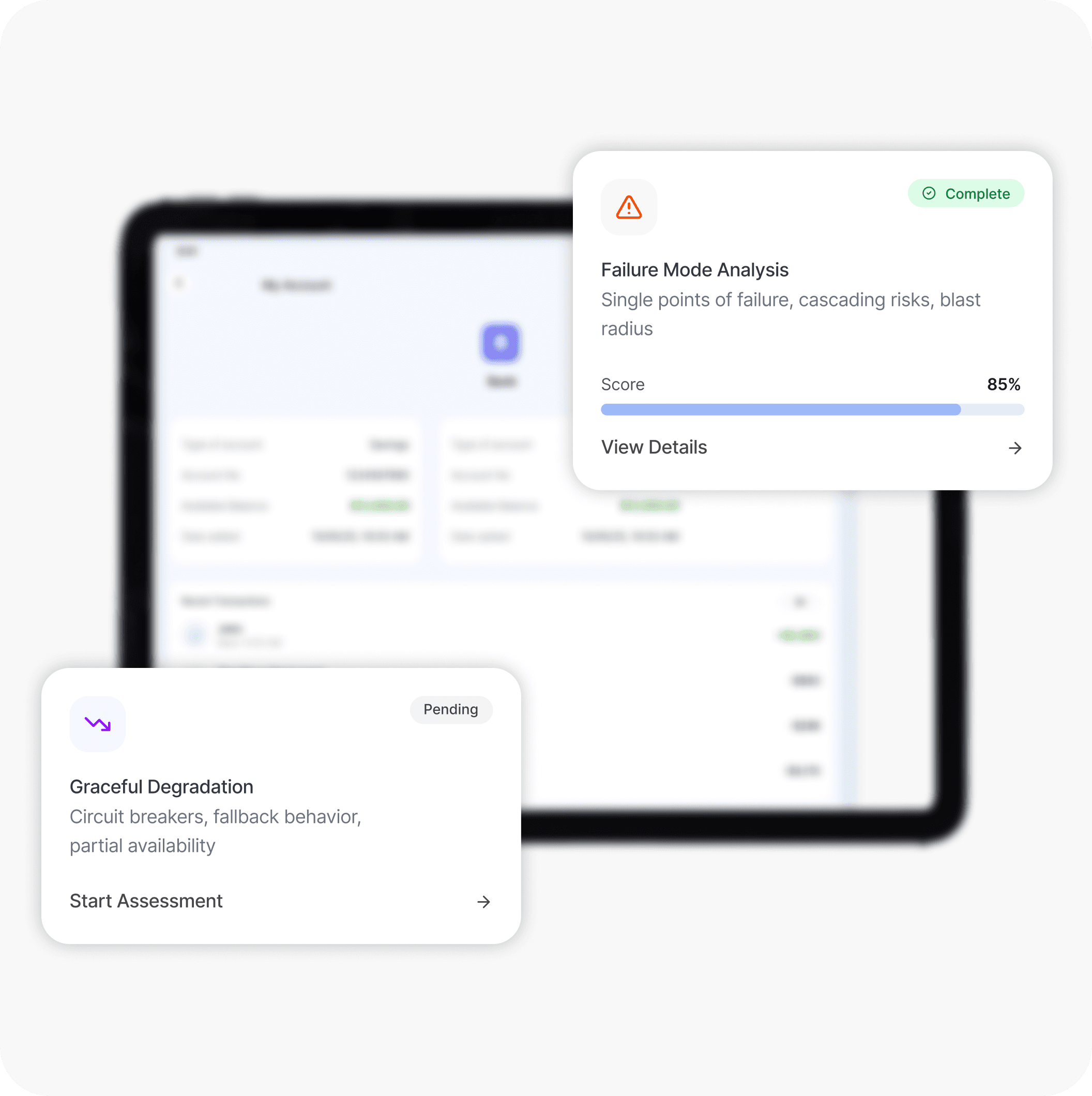
Recurring Patterns We Uncover Across FinOps Engagements
3–5x
Localized bottlenecks (DB locks, connection pools)
70%
P99 latency spikes
1 in 4
Auto-scaling policies cause failure
40%
Average "Zombie" spend
Our Promise
Performance Outcomes We Are Accountable For Delivering
Our scaling and performance planning methodology identifies every scalability constraint before it becomes a customer-facing incident. The deliverables we produce give your organisation the architectural clarity and operational confidence to pursue growth without being ambushed by the infrastructure it demands.
Eliminate the Fear That Comes With Every Traffic Spike
Understand precisely where your system begins to degrade under load and what specific changes eliminate those boundaries — so your team watches growth metrics with anticipation rather than anxiety.
Scale Your Product Without Scaling Your Operational Complexity
Remove the architectural constraints that force manual intervention every time usage increases, so your infrastructure grows alongside your user base without demanding proportional engineering attention.
Deliver Consistent Performance Regardless of Concurrent Demand
Arrive at an architecture where response times, throughput, and reliability metrics remain predictable whether you are serving your average daily load or your highest traffic peak on record.
Invest in Capacity Where It Generates Return, Not Where It Feels Safe
Receive a precise breakdown of where infrastructure investment delivers measurable performance improvement and where additional spend yields diminishing returns, so every capacity decision is evidence-based.
OUR RANGE OF IMPACT
Industries Across Which We Deliver Scalability and Performance Impact
We design scalability strategies calibrated to the growth trajectories, traffic characteristics, and reliability expectations of each industry we operate within. Our approach consistently prioritises long-term architectural sustainability over short-term performance patches. We understand the seasonal demand patterns, regulatory availability requirements, and competitive performance expectations that shape infrastructure decisions across every vertical we serve. Every industry in our portfolio reflects genuine, hands-on scalability engineering experience rather than advisory familiarity.
THE GEEKYANTS DIFFERENCE
Scalability Assessments Delivered by Engineers Who Have Scaled 1000+ Production Systems
Our practitioners bring performance pattern recognition forged through hundreds of real production scalability engagements across every major cloud platform and technology stack. Your assessment delivers a genuine architectural diagnosis — not a collection of generic best practice recommendations disconnected from your actual system behaviour.
Our AI-enabled engineers and performance specialists have led scalability transformations across high-traffic, availability-critical platforms in regulated and consumer-facing environments alike.
Every bottleneck, every capacity constraint, and every scaling risk is quantified against your actual traffic patterns and growth projections — not estimated from architectural diagrams alone.
We recommend the scaling patterns, caching strategies, and architectural changes that your specific workload characteristics demand — never the ones that align with a preferred vendor or platform relationship.
Every recommendation we produce is specific, testable, and directly assignable to an engineering team — no translation layer required between assessment output and implementation action.
We document every finding, every architectural decision rationale, and every performance model assumption so your team owns the scalability strategy long after our involvement concludes.
Future Ready
Our Offerings in DevOps Consulting and Services
DevOps Assessment
- Infra, CI/CD & operations health check
- Risk, cost & bottleneck identification
- Clear, prioritized improvement roadmap
CI/CD and Release Management
- Fast, reliable deployment pipelines
- Safer releases with easy rollbacks
- Improved developer delivery velocity
Cloud Infrastructure Management and Deployment
- Day-to-day infrastructure operations & support
- Stable, secure cloud environments
- Reduced operational overhead for teams
Deployment and Infrastructure Automation
- Automated provisioning of infrastructure & deployments
- Reduced manual errors and toil
- Consistent environments across stages
Infrastructure as Code
- Version-controlled cloud infrastructure
- Reproducible and auditable environments
- Standardized app and system configuration
Containerization and Kubernetes
- Application containerization
- Pragmatic Kubernetes adoption
- Scalable and portable runtime platform
Observability- Monitoring, Logging & Alerts
- Full system visibility and metrics
- Faster issue detection and debugging
- Reduced the production of firefighting
Cost Optimization and FinOps
- Cloud cost visibility and tracking
- Waste elimination without slowing teams
- Predictable and efficient cloud spend
Cloud Migration and Modernization
- Low-risk cloud migrations
- Legacy workload modernization
- Simplified and future-ready infrastructure
Scalability and Performance Planning
- Traffic and load readiness analysis
- Bottleneck and capacity planning
- Scale-ready architecture guidance
FEATURED CONTENT
Our Latest Thinking in DevOps
Discover the latest blogs on Our Latest Thinking in DevOps, covering trends, strategies, and real-world case studies.

Technology
Jun 27, 2026
Building a Resilient Hybrid-Cloud Network with WireGuard HA, Route-Based Failover, and Deep Observability
A practical breakdown of building resilient AWS-to-on-premises connectivity with WireGuard HA, active-standby failover, and deep packet-forwarding observability.

Technology
Jun 19, 2026
We Built a 114-Second AWS-to-Azure Failover. Here’s What We Learned
A practical guide to building a 114-second multi-cloud disaster recovery failover between AWS and Azure — what we built, what broke, and what we learned.

Technology
Jun 12, 2026
Cloud-Native and Cloud-Agnostic Are Not Ideologies; They Are Business-Stage Decisions
This blog explains how organizations can balance speed, scalability, and operational flexibility as they grow from startup to enterprise scale.

AI
Apr 7, 2026
How We Built an AI Agent That Fixes CI/CD Pipeline Failures Automatically
A deep dive into how we built an autonomous AI agent that detects and fixes CI/CD pipeline failures without human intervention.

Technology
Apr 6, 2026
AI Code Healer for Fixing Broken CI/CD Builds Fast
A deep dive into how GeekyAnts built an AI-powered Code Healer that analyzes CI/CD failures, summarizes logs, and generates code-level fixes to keep development moving.

Business
Feb 12, 2026
How Lack of Infrastructure Ownership Might Be Killing Your ROI
Cloud costs are spiralling out of control? Learn how lack of infrastructure ownership creates hidden waste, slows teams, and kills ROI. See how to fix it.
Build with us.Accelerate your Growth.
Customized solutions and strategiesFaster-than-market project deliveryEnd-to-end digital transformation services
Trusted By
Book a Discovery Call
Build with us.Accelerate your Growth.
- Customized solutions and strategies
- Faster-than-market project delivery
- End-to-end digital transformation services
Trusted By
What You Need to Know
FAQs About Scalability & Performance Planning Assessment Services
A Scalability & Performance Assessment is a thorough technical investigation of your current architecture, application behaviour under load, database performance characteristics, and operational readiness to manage growth. It identifies every bottleneck constraining your current capacity, maps the failure modes your system will encounter as usage grows, and surfaces the architectural changes, caching strategies, and scaling configurations that will deliver the most meaningful performance improvement per unit of engineering investment. You receive a complete performance profile of your existing system alongside a phased improvement roadmap sequenced by impact and implementation complexity.