Reliability and Production Readiness
We assess your system's failure tolerance, incident response maturity, and operational resilience so you gain complete clarity on where your production environment is fragile, what reliability gaps are putting your service commitments at risk, and the most direct path to building systems that hold up when it matters most.

100+Reviews
1000+Projects Delivered
Stop Hoping Your Systems Stay Up. Start Knowing They Will
550+ Engagements Since 2006 — Trusted By
Most engineering teams only discover the true state of their production readiness when an outage is already underway and customers are already affected. Our Reliability & Production Readiness Assessment surfaces every fragility, every single point of failure, and every operational gap before your users encounter the consequences.
Your incident response becomes structured and repeatable, unplanned downtime stops defining your on-call culture, and the systems you operate genuinely reflect the availability commitments your business has made. You leave holding a detailed, sequenced improvement roadmap your engineers can begin executing immediately.
CUSTOMER STORIES
Client Results and Success
WHAT WE DO
Our Reliability Assessment Examines Three Critical Dimensions
Every engagement opens with a structured, evidence-based evaluation covering three foundational aspects of your production readiness: your system's architectural resilience, your operational incident management maturity, and your team's preparedness to sustain reliability as your platform evolves and scales. We never assess production readiness through documentation reviews and stakeholder interviews alone.
Our AI-empowered engineers examine your actual system configurations, your real alert history, your genuine runbooks, your deployment procedures, and your post-incident reports. The outcome is an honest picture of where your production environment is genuinely robust, where it is held together by institutional knowledge and individual heroics, and where a single unexpected failure could cascade into a significant customer-facing event.
Architectural Resilience Review
Incident Response Maturity Assessment
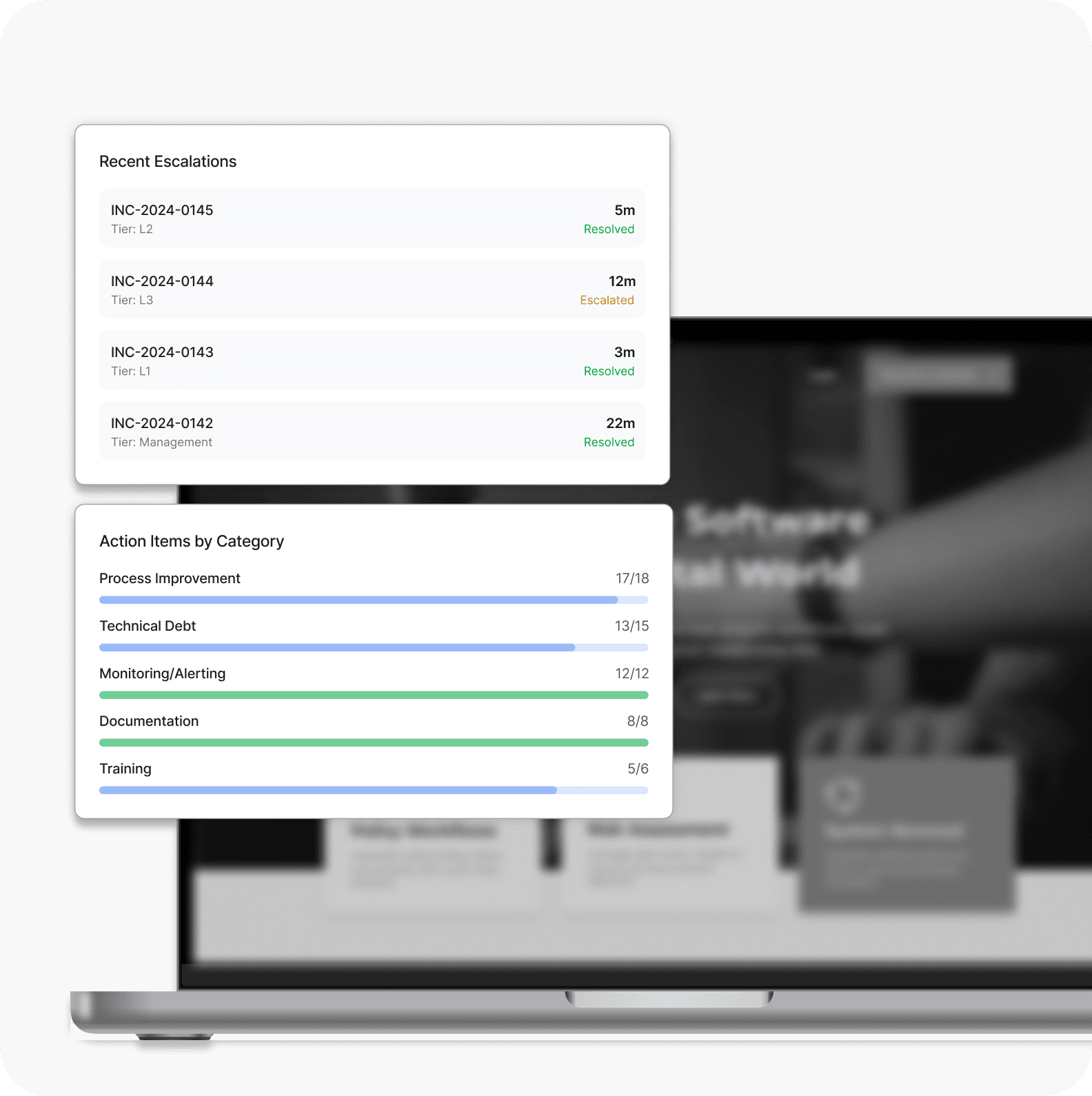
Operational Production Readiness Review
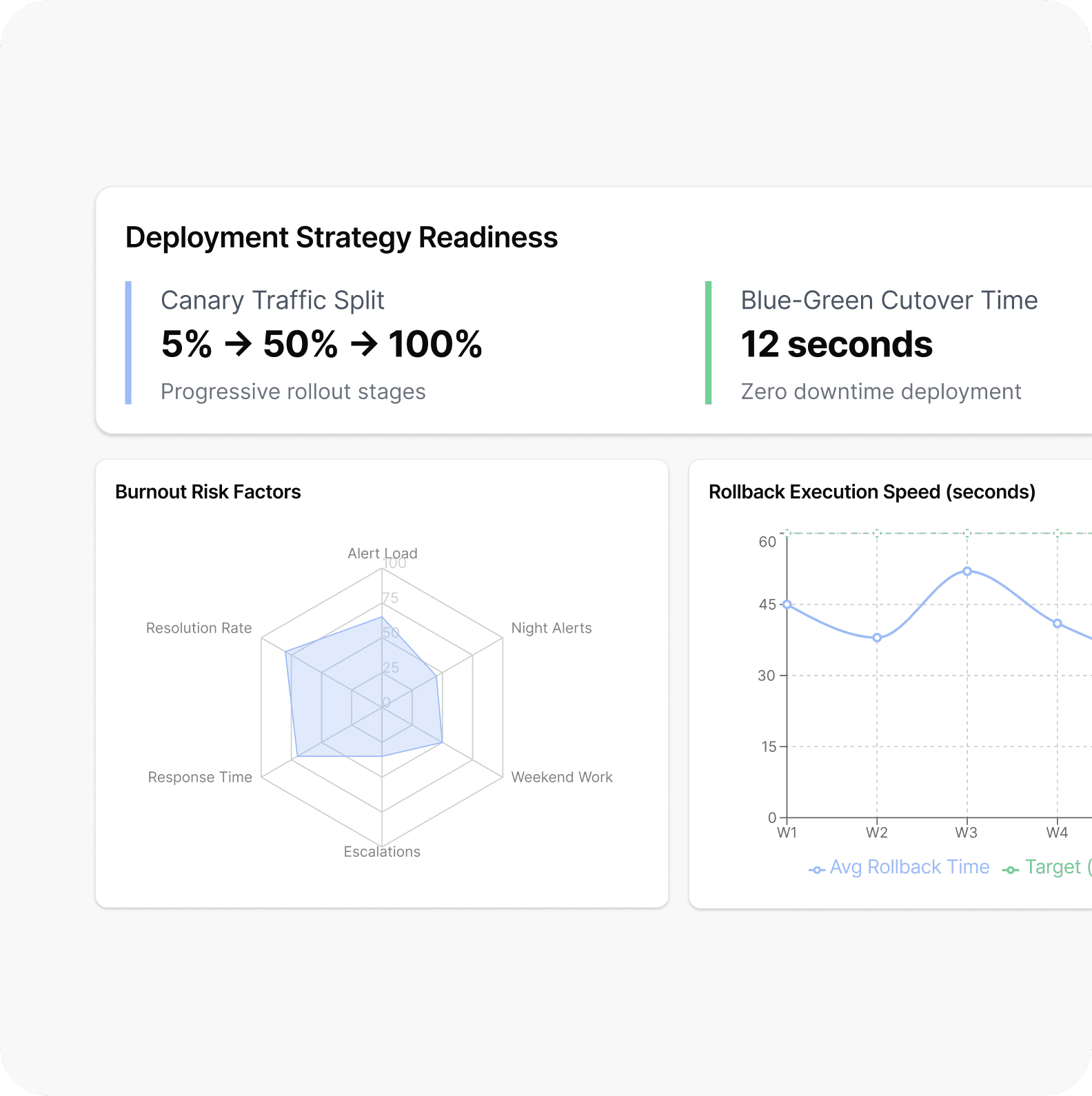
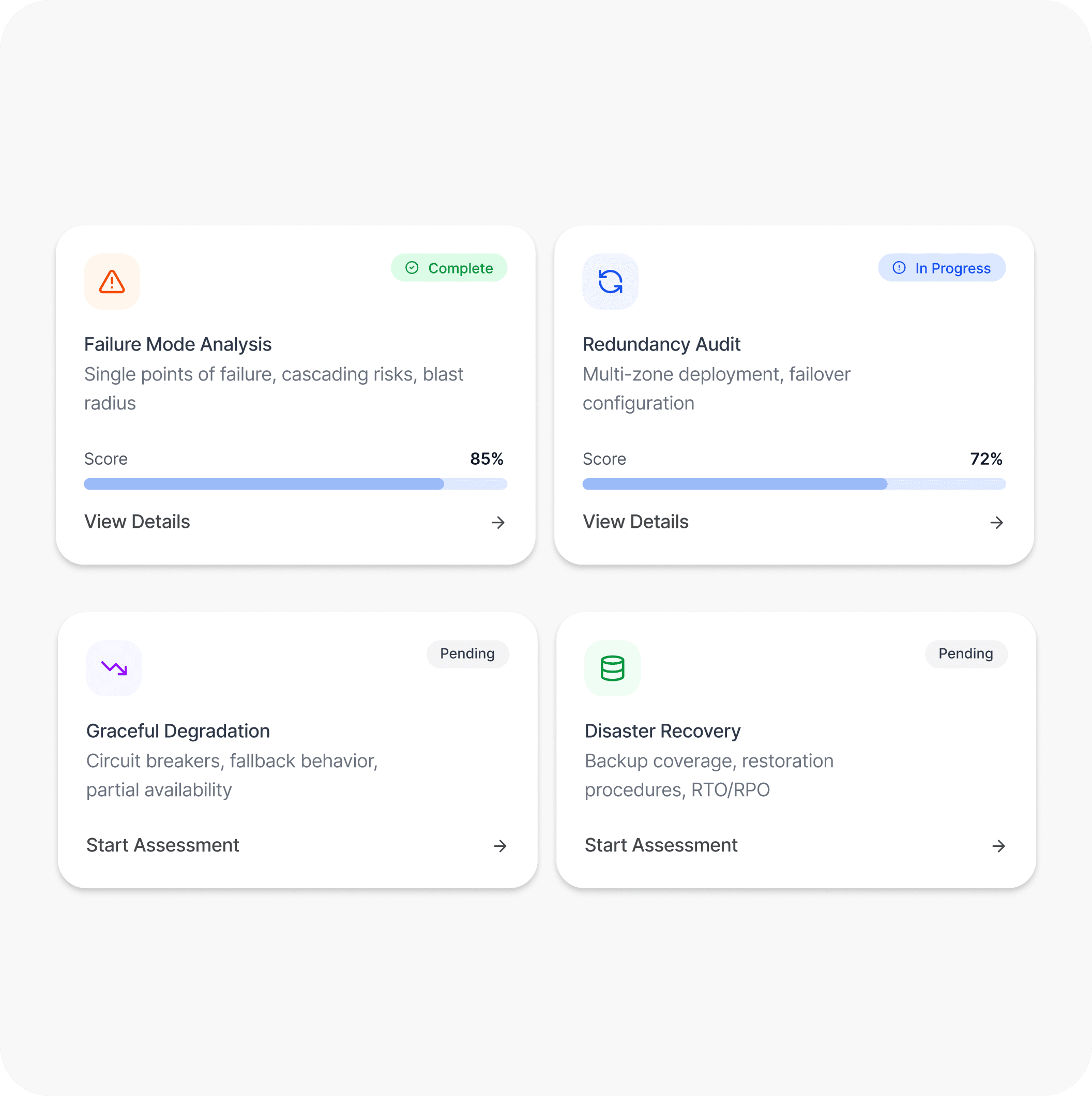
Patterns We Consistently Surface During Reliability Engagements
4-8 hrs
Typical mean time to recovery in teams without structured runbooks and validated escalation paths
60-70%
Proportion of production incidents that were detectable earlier with improved alerting coverage and thresholds
1 in 3
Systems with disaster recovery procedures documented but never tested against a realistic failure simulation
35%
Average reduction in incident frequency achievable through targeted architectural resilience improvements
Our Promise
Reliability Outcomes We Are Accountable For Delivering
Our assessment methodology exposes every fragility before it becomes an outage that your customers experience. The deliverables we produce give your organisation the operational clarity and architectural confidence to pursue growth without reliability becoming the constraint that holds everything else back.
Know Exactly How Your System Fails Before Your Users Do
Understand every failure mode, every cascading dependency risk, and every recovery gap in your current architecture — so your team is never surprised by an incident that a structured assessment would have anticipated.
Make Every Deployment a Controlled Event, Not a Calculated Gamble
Eliminate the uncertainty that surrounds every release by establishing the safety mechanisms, rollback procedures, and deployment validation practices that turn shipping to production into a routine operation.
Build an On-Call Culture Based on Process, Not Heroics
Replace the institutional knowledge and individual dependency that sustains most incident response with documented, validated procedures that any engineer on your team can execute effectively under pressure.
Achieve the Availability Your Business Has Committed to Delivering
Align your architectural resilience, operational procedures, and monitoring coverage to the actual service level objectives your customers depend on — not the aspirational targets nobody has validated.
OUR RANGE OF IMPACT
Industries Across Which We Deliver Reliability and Production Readiness Impact
We understand the compliance requirements around incident documentation, the commercial consequences of unplanned downtime, and the human factors that determine whether incident response procedures actually work when production is burning. Every industry in our portfolio reflects genuine, hands-on reliability engineering experience.
We develop reliability strategies calibrated to the availability expectations, regulatory obligations, and operational consequences of failure that vary meaningfully across every industry we serve. Our approach consistently prioritises sustainable operational resilience over point-in-time fixes that erode under the pressure of ongoing delivery.
THE GEEKYANTS DIFFERENCE
Reliability Assessments Delivered by Engineers Who Have Hardened 1000+ Production Systems
Deep experience across high-stakes production environments has taught us that reliability failures almost never originate from the components engineering teams worry about most. They originate from the dependency everyone assumed was stable, the rollback procedure that had never actually been executed under pressure, the alert that had been silenced because it fired too frequently, and the runbook that described a system three architecture changes out of date.
Our practitioners bring reliability pattern recognition developed through hundreds of production resilience engagements across industries where downtime carries serious commercial, regulatory, and human consequences. Your assessment delivers a genuine operational diagnosis — not a checklist of reliability best practices applied without regard for your specific failure history, architecture, and team dynamics.
Our AI-enabled engineers and reliability specialists have led resilience transformations across availability-critical platforms serving millions of users in regulated and consumer-facing environments.
Every fragility, every recovery gap, and every operational risk is characterised against your actual incident history, your real alert volumes, and your genuine deployment frequency — not against theoretical reliability frameworks.
We recommend the architectural patterns, operational procedures, and monitoring configurations that match your specific availability requirements and team capabilities — never generic SRE practices disconnected from your operational reality.
Every improvement we recommend is scoped, sequenced, and described with sufficient specificity to assign directly to an engineering team and begin without further elaboration or external guidance.
We document every finding, every architectural rationale, and every procedural recommendation so your team owns the reliability programme fully and sustainably from the moment our engagement concludes.
Future Ready
Our Offerings in DevOps Consulting and Services
DevOps Assessment
- Infra, CI/CD & operations health check
- Risk, cost & bottleneck identification
- Clear, prioritized improvement roadmap
CI/CD and Release Management
- Fast, reliable deployment pipelines
- Safer releases with easy rollbacks
- Improved developer delivery velocity
Cloud Infrastructure Management and Deployment
- Day-to-day infrastructure operations & support
- Stable, secure cloud environments
- Reduced operational overhead for teams
Deployment and Infrastructure Automation
- Automated provisioning of infrastructure & deployments
- Reduced manual errors and toil
- Consistent environments across stages
Infrastructure as Code
- Version-controlled cloud infrastructure
- Reproducible and auditable environments
- Standardized app and system configuration
Containerization and Kubernetes
- Application containerization
- Pragmatic Kubernetes adoption
- Scalable and portable runtime platform
Observability- Monitoring, Logging & Alerts
- Full system visibility and metrics
- Faster issue detection and debugging
- Reduced the production of firefighting
Cost Optimization and FinOps
- Cloud cost visibility and tracking
- Waste elimination without slowing teams
- Predictable and efficient cloud spend
Cloud Migration and Modernization
- Low-risk cloud migrations
- Legacy workload modernization
- Simplified and future-ready infrastructure
Scalability and Performance Planning
- Traffic and load readiness analysis
- Bottleneck and capacity planning
- Scale-ready architecture guidance
FEATURED CONTENT
Our Latest Thinking in DevOps
Discover the latest blogs on Our Latest Thinking in DevOps, covering trends, strategies, and real-world case studies.

Technology
Jun 27, 2026
Building a Resilient Hybrid-Cloud Network with WireGuard HA, Route-Based Failover, and Deep Observability
A practical breakdown of building resilient AWS-to-on-premises connectivity with WireGuard HA, active-standby failover, and deep packet-forwarding observability.

Technology
Jun 19, 2026
We Built a 114-Second AWS-to-Azure Failover. Here’s What We Learned
A practical guide to building a 114-second multi-cloud disaster recovery failover between AWS and Azure — what we built, what broke, and what we learned.

Technology
Jun 12, 2026
Cloud-Native and Cloud-Agnostic Are Not Ideologies; They Are Business-Stage Decisions
This blog explains how organizations can balance speed, scalability, and operational flexibility as they grow from startup to enterprise scale.

AI
Apr 7, 2026
How We Built an AI Agent That Fixes CI/CD Pipeline Failures Automatically
A deep dive into how we built an autonomous AI agent that detects and fixes CI/CD pipeline failures without human intervention.

Technology
Apr 6, 2026
AI Code Healer for Fixing Broken CI/CD Builds Fast
A deep dive into how GeekyAnts built an AI-powered Code Healer that analyzes CI/CD failures, summarizes logs, and generates code-level fixes to keep development moving.

Business
Feb 12, 2026
How Lack of Infrastructure Ownership Might Be Killing Your ROI
Cloud costs are spiralling out of control? Learn how lack of infrastructure ownership creates hidden waste, slows teams, and kills ROI. See how to fix it.
Build with us.Accelerate your Growth.
Customized solutions and strategiesFaster-than-market project deliveryEnd-to-end digital transformation services
Trusted By
Book a Discovery Call
Build with us.Accelerate your Growth.
- Customized solutions and strategies
- Faster-than-market project delivery
- End-to-end digital transformation services
Trusted By
What You Need to Know
FAQs About Reliability and Production Readiness Assessment Services
A Reliability & Production Readiness Assessment is a comprehensive audit of your system's architectural resilience, incident response maturity, and operational sustainability. It identifies every single point of failure in your current architecture, maps the cascading failure scenarios your system is exposed to, evaluates the completeness and accuracy of your runbooks and escalation procedures, and surfaces the gaps between the availability commitments your business has made and the operational infrastructure supporting them. You receive a complete reliability profile of your production environment alongside a prioritised improvement roadmap that sequences interventions by their impact on availability, recovery speed, and on-call sustainability.