Containerization and Kubernetes
Your infrastructure shouldn't require a specialist on call every time something needs to scale, recover, or ship.
We design and operate container infrastructure that runs predictably under pressure — so your engineering team spends less time managing environments and more time building the product.

100+Reviews
1000+Projects Delivered
Move From Fragile Infrastructure to Container-Native Architecture
550+ Engagements Since 2006 — Trusted By
Most container infrastructure problems don't start with Kubernetes. They start with decisions made before Kubernetes was in the picture — services that weren't designed to run in containers, clusters that were stood up without a day-two operations plan, and workloads that scaled fine in staging but fell apart under real traffic.
By the time those problems surface, they're expensive to fix and hard to explain to leadership. Our Containerization and Kubernetes service is built around preventing that outcome. We assess where your container strategy is creating risk or holding back delivery, then build the infrastructure layer your platform needs to scale — without the operational weight that normally comes with it.
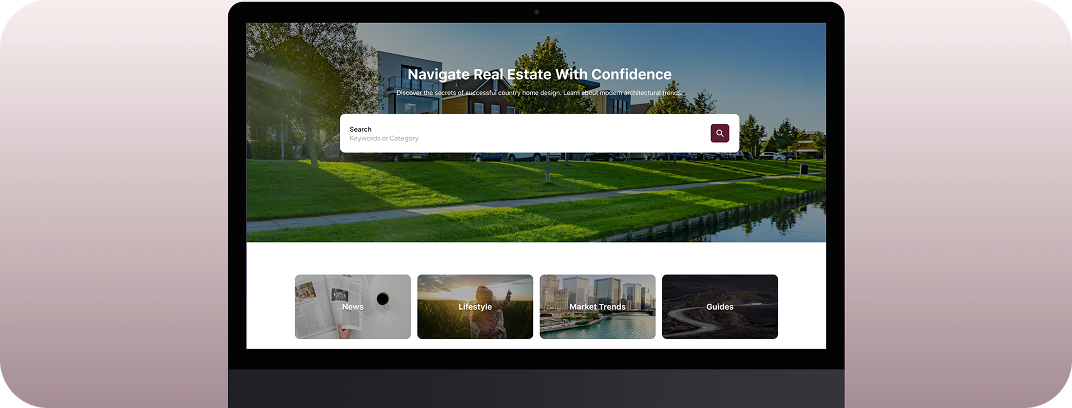
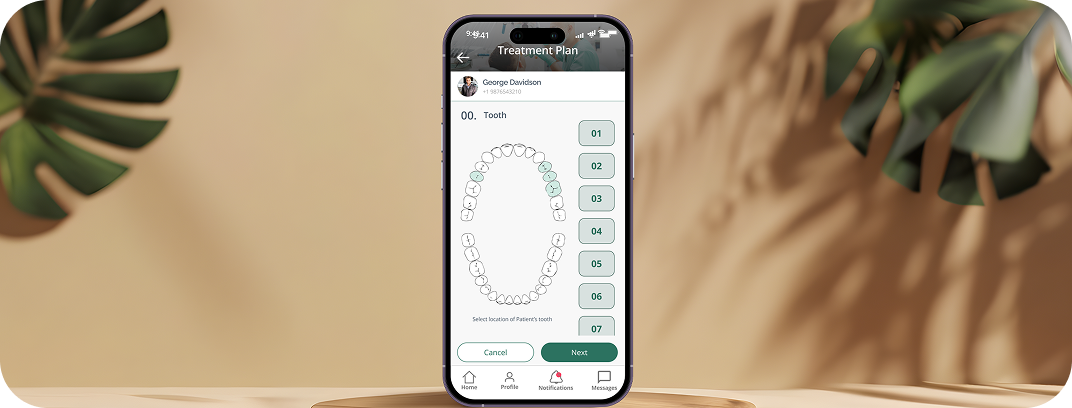
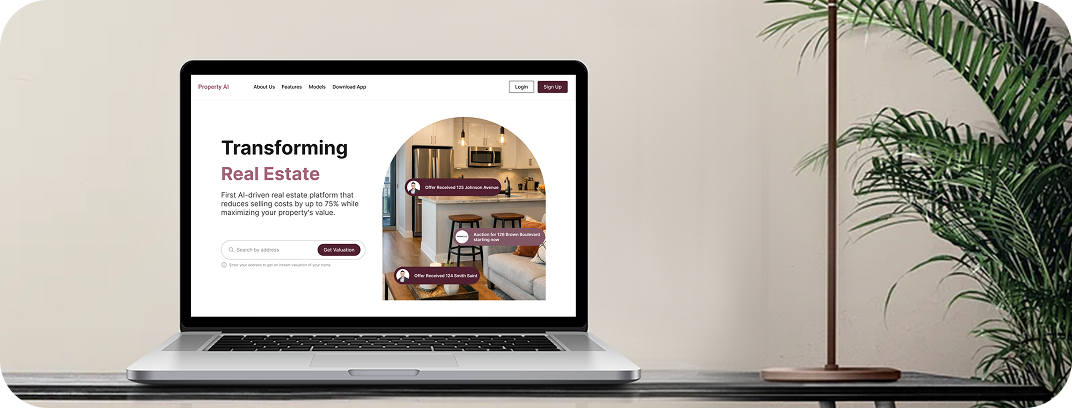
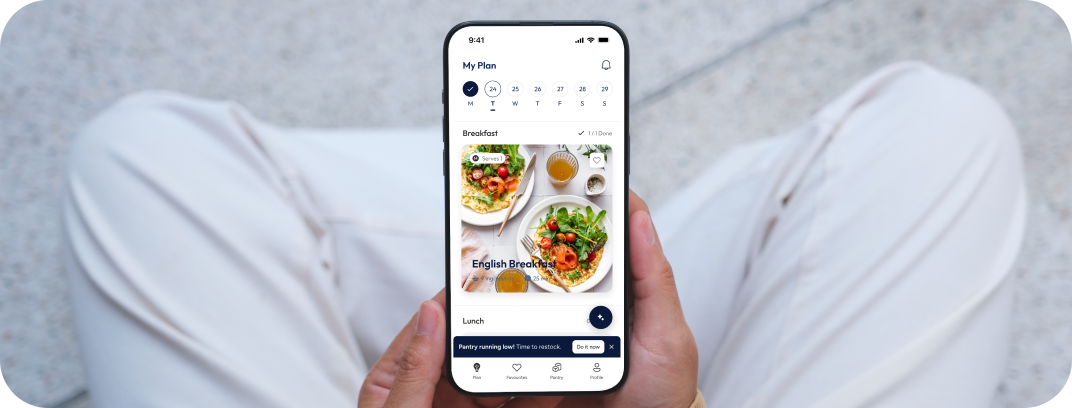
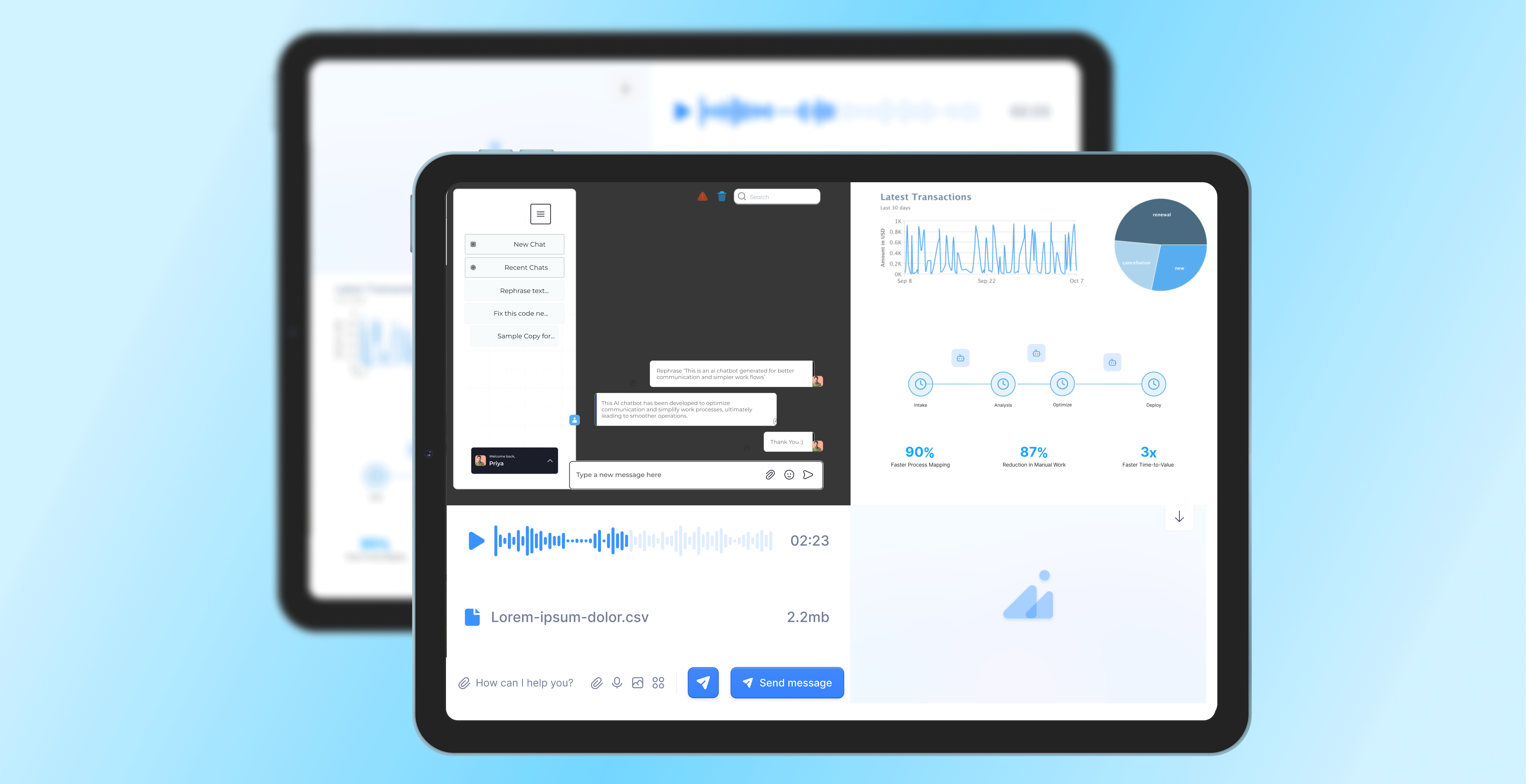
CUSTOMER STORIES
Client Results and Success
WHAT WE DO
Our Containerization and Kubernetes Services
Running containers in production is a different discipline from getting them working in a demo. The failure modes are different, the operational requirements are different, and the cost of getting it wrong shows up in ways that are hard to trace back to their origin. Our services are built for teams that need container infrastructure to actually hold up — at scale, under load, and without requiring constant expert attention.
Containerization Strategy and Implementation
Kubernetes Cluster Design and Operations

Scaling, Reliability, and Day-Two Operations

Observability and Incident Response


INDUSTRY EXPERTISE
Containerization And Kubernetes Across Every Industry
CTOs and engineering leaders don't invest in Kubernetes because it's technically interesting. They invest because unreliable infrastructure is expensive — in engineering time, in incident response, in delayed releases, and in cloud spend that doesn't map to value delivered. This is what changes.
Infrastructure That Holds Up When Traffic Doesn't Behave
Properly configured autoscaling and pod-level resilience mean your platform responds to demand spikes without manual intervention and recovers from failures without your team being paged at 2 am.
Release Confidence Across Every Environment
Container-native delivery means the same image that passed testing is what reaches production. Environment-specific failures stop being a regular occurrence.
Infrastructure Costs Proportional to Real Demand
Right-sized containers and intelligent autoscaling mean you pay for what your workloads need when they need it — not for headroom that exists to compensate for infrastructure you don't fully understand.
Engineering Time Back Where It Belongs
When your container infrastructure is designed properly and documented thoroughly, it stops consuming engineering attention. Your senior engineers work on problems that move the product forward, not on keeping the cluster stable.
OUR RANGE OF IMPACT
Kubernetes and Containerization Across Every Industry
Container infrastructure requirements vary significantly depending on the industry. A fintech platform running under PCI-DSS has fundamentally different cluster security requirements than a consumer app optimising for release velocity. A healthcare system operating under HIPAA needs audit trails and access controls baked into the container layer. A high-traffic e-commerce platform needs autoscaling that responds in seconds, not minutes.
We design container infrastructure around the operational and compliance reality of the industry you operate in — not a generalised Kubernetes template adapted after the fact.
THE GEEKYANTS DIFFERENCE
Kubernetes Engineering from a Team That Has Operated It in Production Across 1000+ Projects
There's a significant gap between teams that have deployed Kubernetes and teams that have operated it — through scaling incidents, misconfigured RBAC, node pool exhaustion, and workloads that behaved perfectly in staging and failed in ways nobody anticipated in production.
We sit firmly in the second category. The experience we bring to your engagement isn't theoretical. It comes from years of operating container infrastructure across industries, platform types, and scale ranges where the cost of getting it wrong was real.
The engineers assessing your container infrastructure are the same engineers designing and implementing the solution. There's no account management layer between the conversation and the keyboard.
Cluster design, namespace strategy, scaling configuration, and day-two operations planning are built around your team's size, your release cadence, and your platform's actual traffic behaviour — not a generic configuration that approximately fits.
We work across EKS, GKE, AKS, and self-managed Kubernetes, with hands-on depth in Helm, ArgoCD, Istio, Prometheus, Grafana, Datadog, Terraform, Pulumi, and more. Recommendations are driven by what your environment needs — not tooling preferences.
Every cluster, Helm chart, runbook, and configuration file we deliver is production-ready and documented for long-term operation by your team. The handover is complete — not a starting point that still requires our involvement.
Structured knowledge transfer, operational documentation, and architecture decision records give the engineers inheriting the system the context to operate it confidently and make good decisions about where it goes next.
Future Ready
Our Offerings in DevOps Consulting and Services
DevOps Assessment
- Infra, CI/CD & operations health check
- Risk, cost & bottleneck identification
- Clear, prioritized improvement roadmap
CI/CD and Release Management
- Fast, reliable deployment pipelines
- Safer releases with easy rollbacks
- Improved developer delivery velocity
Cloud Infrastructure Management and Deployment
- Day-to-day infrastructure operations & support
- Stable, secure cloud environments
- Reduced operational overhead for teams
Deployment and Infrastructure Automation
- Automated provisioning of infrastructure & deployments
- Reduced manual errors and toil
- Consistent environments across stages
Infrastructure as Code
- Version-controlled cloud infrastructure
- Reproducible and auditable environments
- Standardized app and system configuration
Containerization and Kubernetes
- Application containerization
- Pragmatic Kubernetes adoption
- Scalable and portable runtime platform
Observability- Monitoring, Logging & Alerts
- Full system visibility and metrics
- Faster issue detection and debugging
- Reduced the production of firefighting
Cost Optimization and FinOps
- Cloud cost visibility and tracking
- Waste elimination without slowing teams
- Predictable and efficient cloud spend
Cloud Migration and Modernization
- Low-risk cloud migrations
- Legacy workload modernization
- Simplified and future-ready infrastructure
Scalability and Performance Planning
- Traffic and load readiness analysis
- Bottleneck and capacity planning
- Scale-ready architecture guidance
FEATURED CONTENT
Our Latest Thinking in DevOps
Discover the latest blogs on Our Latest Thinking in DevOps, covering trends, strategies, and real-world case studies.

Technology
Jun 27, 2026
Building a Resilient Hybrid-Cloud Network with WireGuard HA, Route-Based Failover, and Deep Observability
A practical breakdown of building resilient AWS-to-on-premises connectivity with WireGuard HA, active-standby failover, and deep packet-forwarding observability.

Technology
Jun 19, 2026
We Built a 114-Second AWS-to-Azure Failover. Here’s What We Learned
A practical guide to building a 114-second multi-cloud disaster recovery failover between AWS and Azure — what we built, what broke, and what we learned.

Technology
Jun 12, 2026
Cloud-Native and Cloud-Agnostic Are Not Ideologies; They Are Business-Stage Decisions
This blog explains how organizations can balance speed, scalability, and operational flexibility as they grow from startup to enterprise scale.

AI
Apr 7, 2026
How We Built an AI Agent That Fixes CI/CD Pipeline Failures Automatically
A deep dive into how we built an autonomous AI agent that detects and fixes CI/CD pipeline failures without human intervention.

Technology
Apr 6, 2026
AI Code Healer for Fixing Broken CI/CD Builds Fast
A deep dive into how GeekyAnts built an AI-powered Code Healer that analyzes CI/CD failures, summarizes logs, and generates code-level fixes to keep development moving.

Business
Feb 12, 2026
How Lack of Infrastructure Ownership Might Be Killing Your ROI
Cloud costs are spiralling out of control? Learn how lack of infrastructure ownership creates hidden waste, slows teams, and kills ROI. See how to fix it.
Build with us.Accelerate your Growth.
Customized solutions and strategiesFaster-than-market project deliveryEnd-to-end digital transformation services
Trusted By
Book a Discovery Call
Build with us.Accelerate your Growth.
- Customized solutions and strategies
- Faster-than-market project delivery
- End-to-end digital transformation services
Trusted By
What You Need to Know
FAQs About Containerization And Kubernetes
Not necessarily — but it depends on where you're headed. Containers without orchestration work well up to a point. When services multiply, traffic patterns become unpredictable, or release cadence increases, the absence of orchestration tends to show up as operational overhead and scaling constraints. We help teams assess whether Kubernetes is the right next step and, if it is, how to make the transition without disruption.