Observability - Monitoring, Logging & Alerts

Make Your Systems Transparent and Traceable
550+ Engagements Since 2006 — Trusted By
Most engineering teams discover the gaps in their observability only after a Tier-1 incident spirals. Our Observability Assessment identifies those blind spots in your monitoring, logging, and alerting before they escalate into outages. We replace chaotic troubleshooting with structured, reliable workflows, drastically reducing alert fatigue and Mean Time to Resolution (MTTR). You’ll walk away with a prioritized, high-impact roadmap your team can execute on Day 1.
CUSTOMER STORIES
Client Results and Success
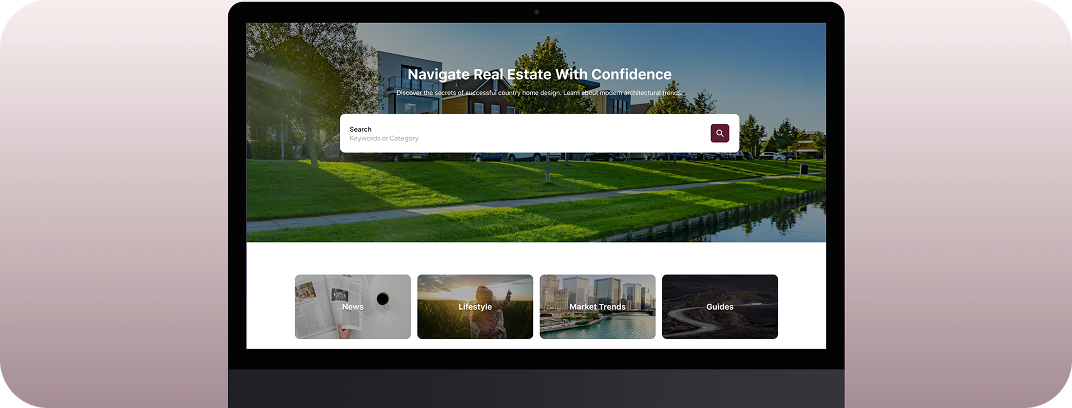
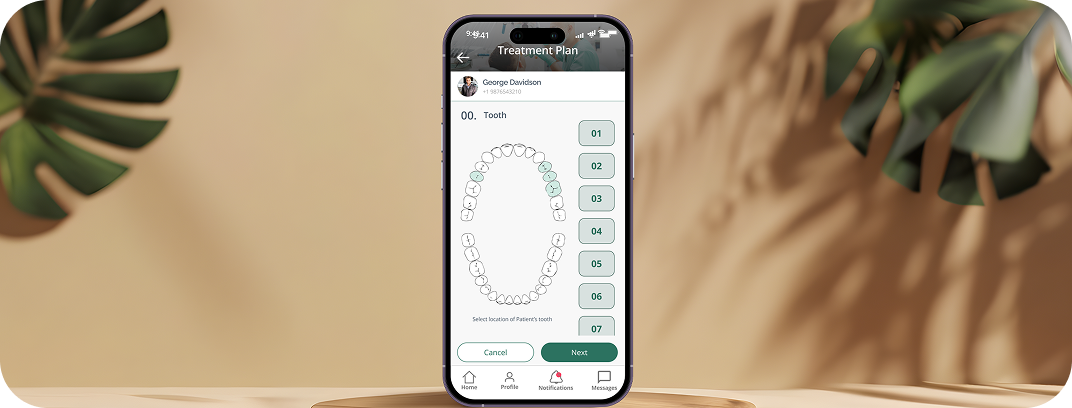
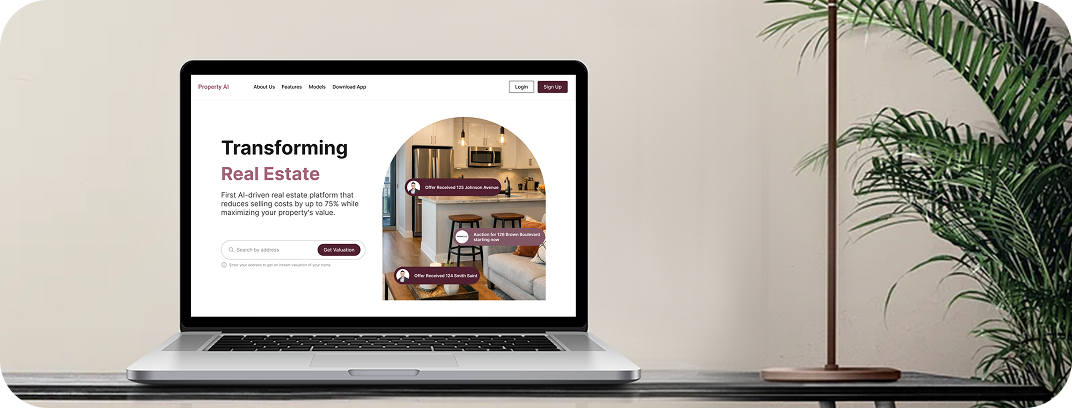
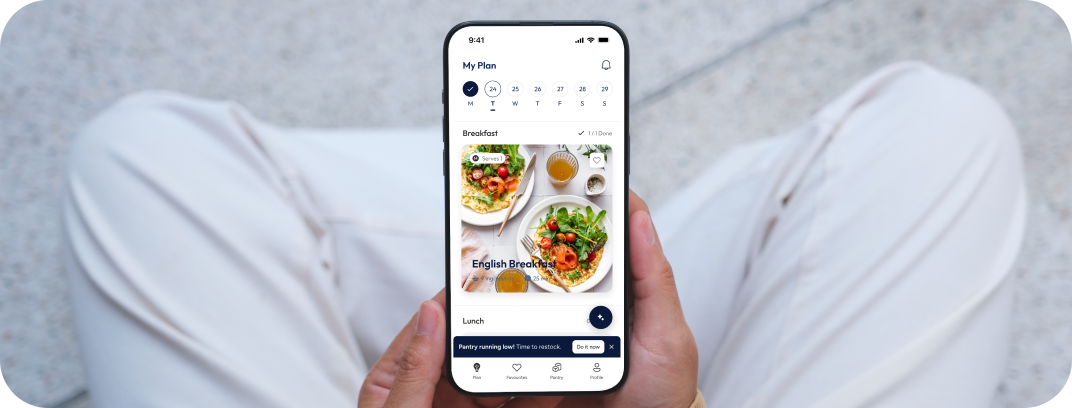
WHAT WE DO
Our Observability Assessment Covers Three Core Areas
Monitoring Coverage Review
Logging Infrastructure Assessment
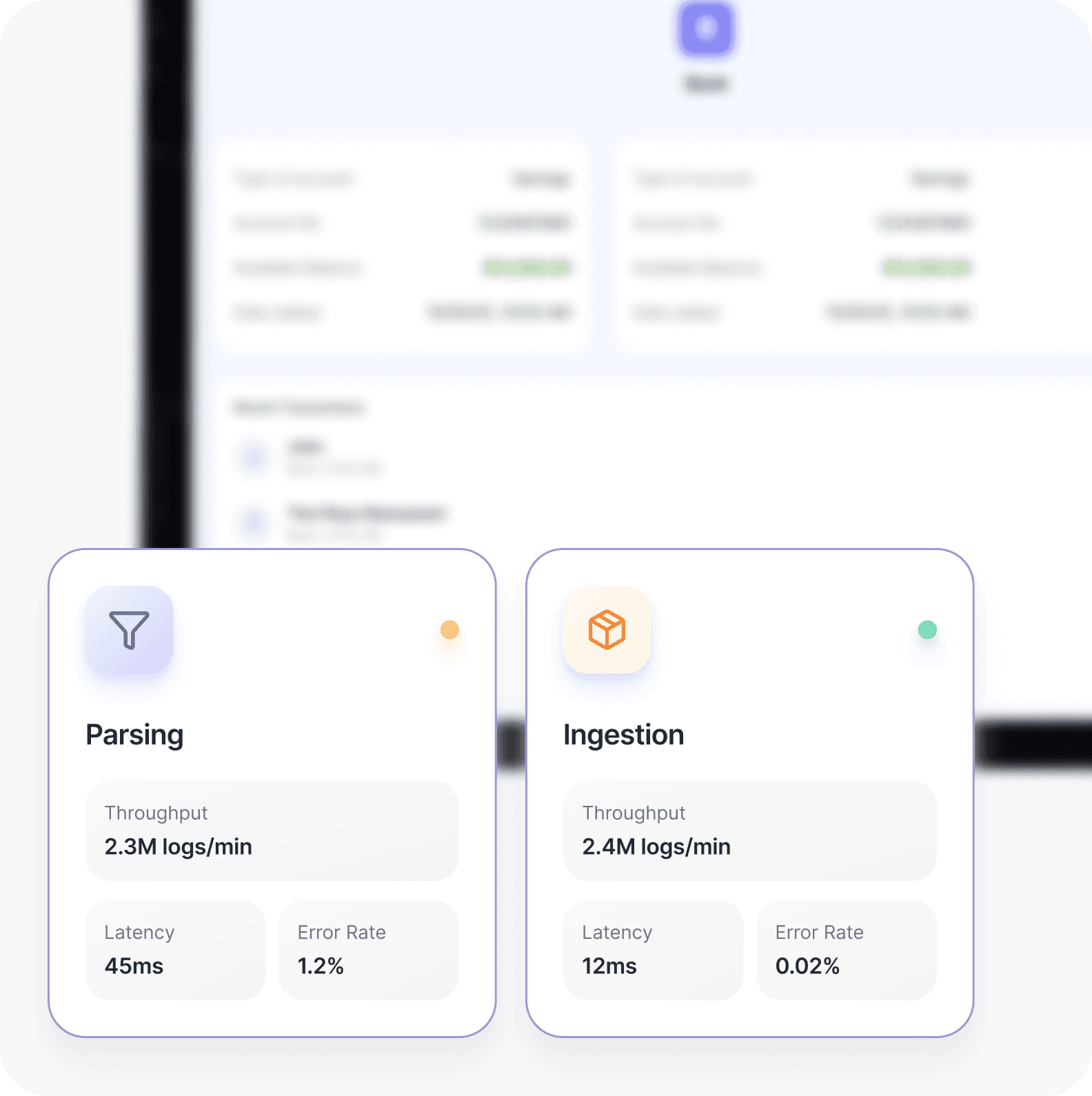
Alerting Maturity Review
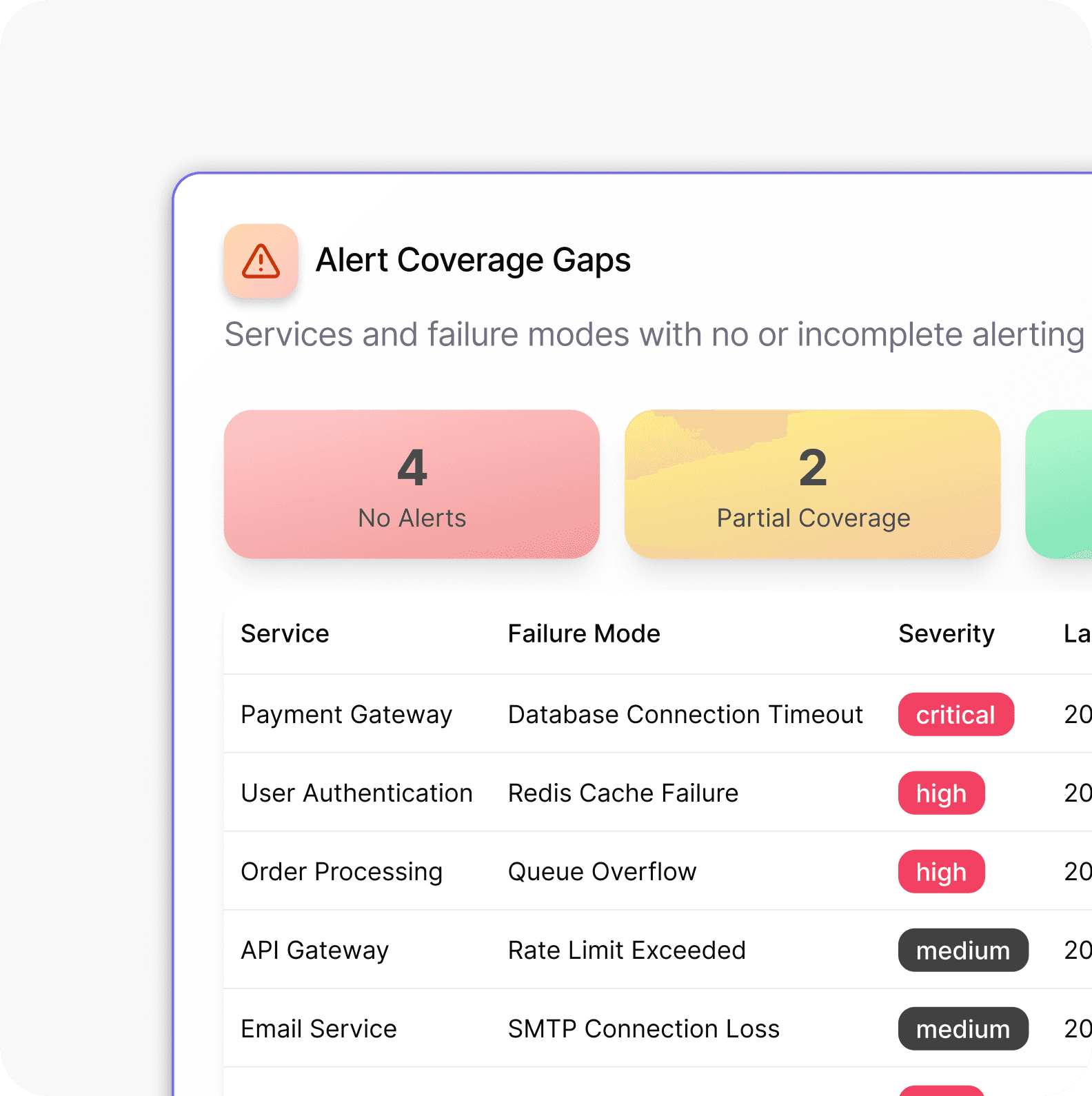
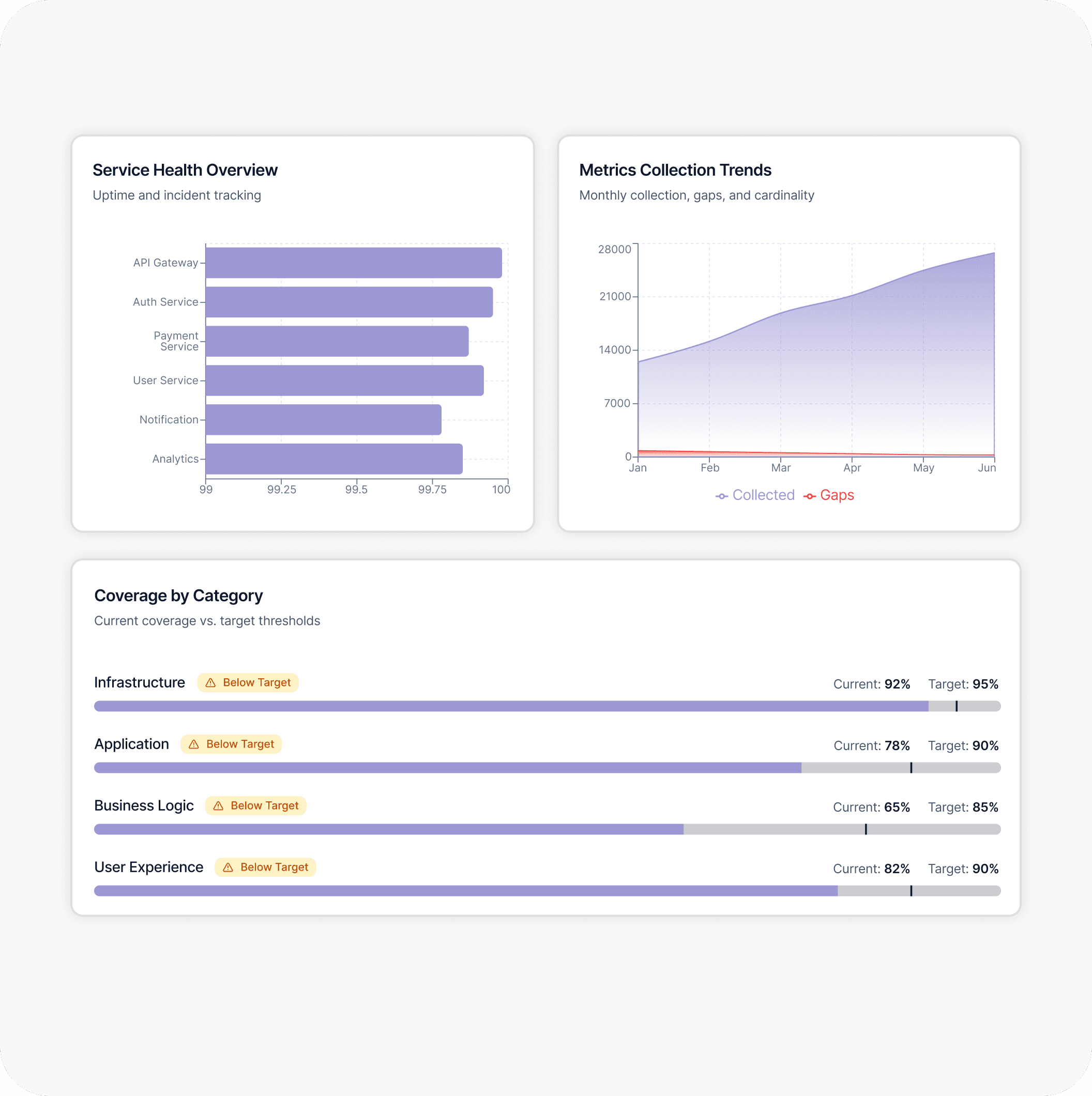
General Issues We Encounter During Our Observability Assessment Engagements
Our Promise
Fixes and Improvements We Provide
OUR RANGE OF IMPACT
Industries We Service
THE GEEKYANTS DIFFERENCE
DevOps Assessments by Engineering Teams that Have Built 1000+ Global Projects
Future Ready
Our Offerings in DevOps Consulting and Services
DevOps Assessment
- Infra, CI/CD & operations health check
- Risk, cost & bottleneck identification
- Clear, prioritized improvement roadmap
CI/CD and Release Management
- Fast, reliable deployment pipelines
- Safer releases with easy rollbacks
- Improved developer delivery velocity
Cloud Infrastructure Management and Deployment
- Day-to-day infrastructure operations & support
- Stable, secure cloud environments
- Reduced operational overhead for teams
Deployment and Infrastructure Automation
- Automated provisioning of infrastructure & deployments
- Reduced manual errors and toil
- Consistent environments across stages
Infrastructure as Code
- Version-controlled cloud infrastructure
- Reproducible and auditable environments
- Standardized app and system configuration
Containerization and Kubernetes
- Application containerization
- Pragmatic Kubernetes adoption
- Scalable and portable runtime platform
Observability- Monitoring, Logging & Alerts
- Full system visibility and metrics
- Faster issue detection and debugging
- Reduced the production of firefighting
Cost Optimization and FinOps
- Cloud cost visibility and tracking
- Waste elimination without slowing teams
- Predictable and efficient cloud spend
Cloud Migration and Modernization
- Low-risk cloud migrations
- Legacy workload modernization
- Simplified and future-ready infrastructure
Scalability and Performance Planning
- Traffic and load readiness analysis
- Bottleneck and capacity planning
- Scale-ready architecture guidance
FEATURED CONTENT
Our Latest Thinking in DevOps

Jun 27, 2026
Building a Resilient Hybrid-Cloud Network with WireGuard HA, Route-Based Failover, and Deep Observability

Jun 19, 2026
We Built a 114-Second AWS-to-Azure Failover. Here’s What We Learned

Jun 12, 2026
Cloud-Native and Cloud-Agnostic Are Not Ideologies; They Are Business-Stage Decisions

Apr 7, 2026
How We Built an AI Agent That Fixes CI/CD Pipeline Failures Automatically

Apr 6, 2026
AI Code Healer for Fixing Broken CI/CD Builds Fast

Feb 12, 2026
How Lack of Infrastructure Ownership Might Be Killing Your ROI
Build with us.Accelerate your Growth.
Customized solutions and strategiesFaster-than-market project deliveryEnd-to-end digital transformation services
Trusted By
Book a Discovery Call
Build with us.Accelerate your Growth.
- Customized solutions and strategies
- Faster-than-market project delivery
- End-to-end digital transformation services
Trusted By
What You Need to Know