Jun 27, 2026
Building a Resilient Hybrid-Cloud Network with WireGuard HA, Route-Based Failover, and Deep Observability
A practical breakdown of building resilient AWS-to-on-premises connectivity with WireGuard HA, active-standby failover, and deep packet-forwarding observability.
Author


Book a call
Table of Contents
Most hybrid-cloud networking discussions eventually converge toward the same set of enterprise-heavy solutions:
- Managed VPN gateways
- MPLS connectivity
- Transit Gateway
- BGP-based active-active architectures
In practice, many engineering teams are solving a much narrower — but operationally critical — problem:
Public cloud applications need reliable, secure access to private on-premises systems without introducing unnecessary networking complexity.
In our case, the requirement initially looked deceptively simple.
We had:
- Public-facing APIs running on AWS
- Internal APIs and databases hosted on-premises
- Strict requirements around resilience and observability
- A need to avoid expensive enterprise networking stacks
Operationally, things became more complicated very quickly.
As traffic increased and failover testing became more realistic, several problems started emerging:
- Tunnel health appeared healthy while application traffic silently failed
- Intermittent packet forwarding issues became difficult to diagnose
- Failover behavior became inconsistent
- Route ambiguity started appearing during dual-path testing
- Monitoring produced false-positive tunnel health
The problem slowly stopped being:
“How do we create secure connectivity?”
and became:
“How do we build predictable, observable, and operationally recoverable hybrid-cloud networking?”
That distinction ended up shaping the entire architecture.
Instead of optimizing for networking sophistication, the final system intentionally optimized for:
- Deterministic failover
- Operational simplicity
- Infrastructure-driven recovery
- Deep packet-forwarding visibility
- Cloud-agnostic portability
The result was a lightweight hybrid-cloud architecture built using:
- WireGuard
- Linux-native routing
- AWS Route Table failover
- Prometheus observability
- Active-standby tunnel paths
The Initial Assumption: One Tunnel Is Enough
The earliest implementation used a single WireGuard tunnel between AWS and the on-premises environment.
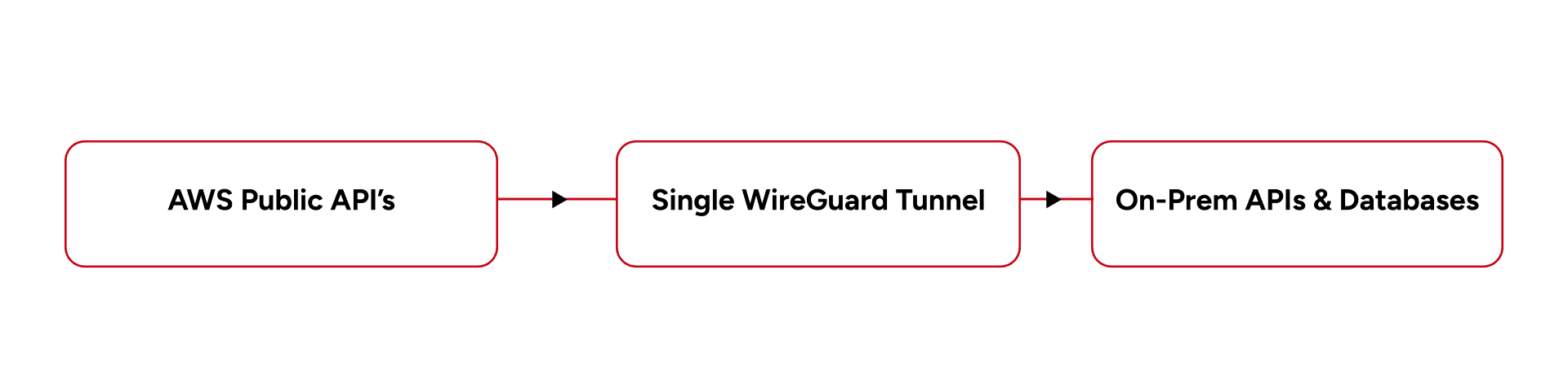
However, failover testing immediately exposed an operational weakness:
The tunnel itself became a single recovery dependency.
Any degradation introduced:
- Backend API timeouts
- Intermittent request failures
- Delayed recovery
- Manual operational intervention
At this stage, the tunnel was technically functional, but operationally fragile.
Why Traditional Enterprise Networking Was Avoided
The obvious next step was evaluating:
- Managed VPN services
- Transit Gateway
- BGP-based routing
- Active-active tunnel fabrics
On paper, these architectures looked attractive.
| Concern | Operational Impact |
|---|---|
| Managed VPN pricing | Difficult to justify at mid-scale |
| Dynamic route convergence | Harder to predict during failures |
| Vendor abstractions | Reduced debugging visibility |
| Active-active routing | Increased troubleshooting complexity |
| BGP failover behavior | Operationally non-deterministic |
One operational realization became increasingly clear during testing:
Faster troubleshooting was consistently more valuable than maximizing tunnel utilization efficiency.
At mid-scale, operational determinism mattered more than networking elegance.
Early Active-Active Experiments Created More Problems Than They Solved
The next iteration experimented with dual active tunnels.
The idea initially seemed straightforward:
- Two active paths
- Traffic balancing
- Higher availability
- Improved utilization
Operationally, this introduced several difficult behaviors.
During partial degradation testing, we observed:
- Asymmetric return traffic
- Intermittent packet forwarding failures
- Route ambiguity inside Linux routing tables
- Inconsistent failover timing
- Hard-to-debug intermittent API failures
One particularly difficult issue appeared when outbound and return traffic took different paths during transient failures.
From the application perspective:
- Some requests succeeded
- Others silently timed out
- Tunnel interfaces still appeared healthy
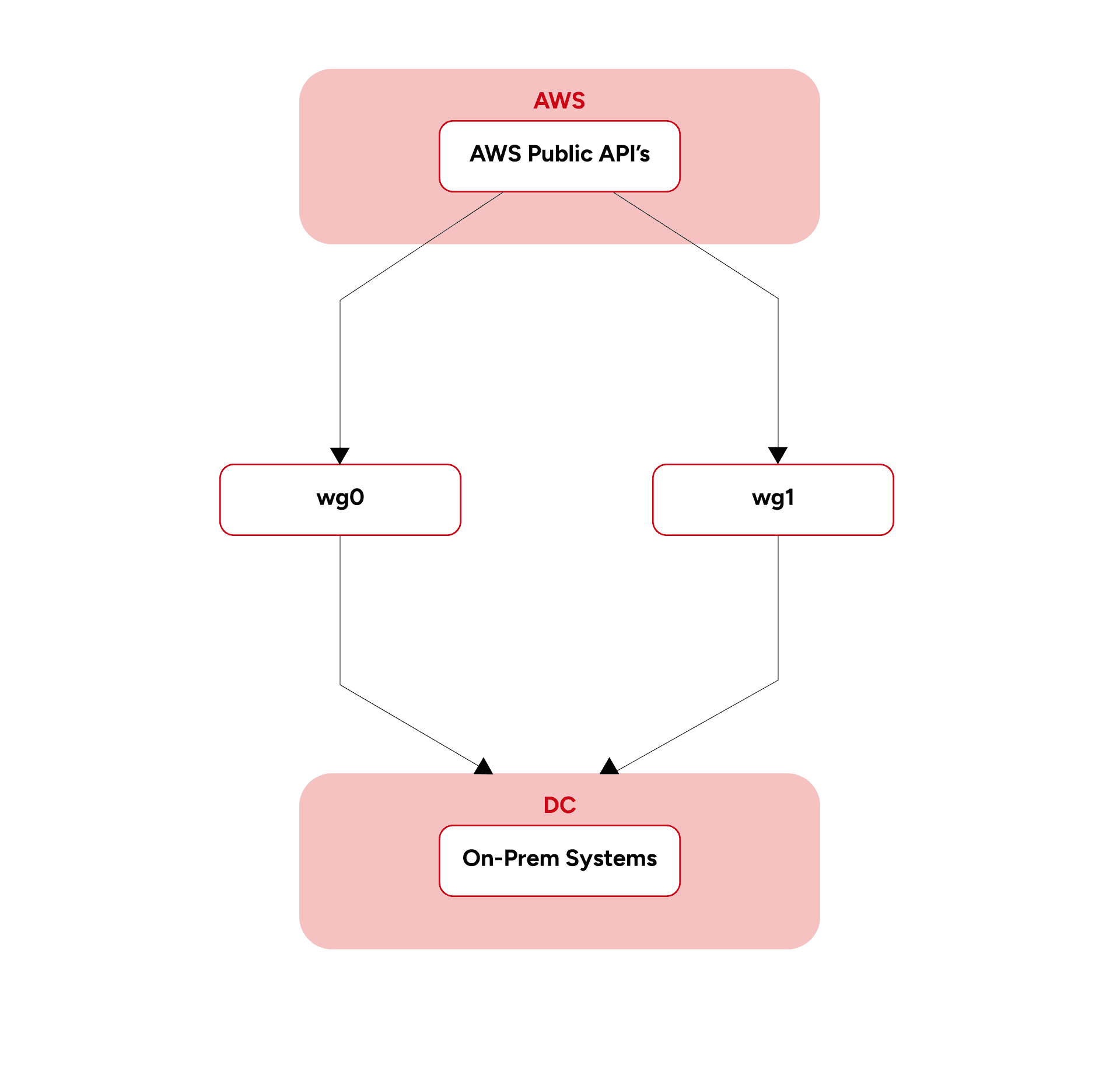
The architecture technically achieved redundancy.
Operationally, it reduced predictability.
Eventually, the team realized:
Deterministic failover behavior was more operationally valuable than active-active utilization efficiency.
Moving Toward Deterministic Routing
Instead of active-active routing, the architecture evolved toward:
- Isolated tunnel paths
- Active-standby failover
- Infrastructure-driven recovery
- Strict subnet separation
Traffic would always prefer a primary path and shift only during validated degradation.
This dramatically simplified:
- Troubleshooting
- Observability
- Routing behavior
- Operational recovery
The system intentionally sacrificed:
- Maximum tunnel utilization
- Dynamic traffic balancing
- Networking sophistication
in exchange for:
- Deterministic failover
- Operational transparency
- Predictable recovery
Final Hybrid-Cloud Architecture
The final design used:
- Two completely isolated WireGuard paths
- Dedicated subnet ownership
- AWS Route Table failover
- Infrastructure-level recovery automation
Why Two Completely Separate Tunnel Paths Worked Better
A common question during architecture reviews was:
Why not use a single HA VPN endpoint?
Operationally, shared tunnel systems introduced several recurring problems:
- Overlapping route ownership
- Shared interface state
- Route recursion issues
- Asymmetric forwarding
- Failover race conditions
Instead, each tunnel path operated independently with:
- Isolated interfaces
- Isolated route ownership
- Isolated health validation
- Isolated failover behavior
This dramatically improved operational visibility during failures.
During testing, failures became:
- Easier to isolate
- Easier to observe
- Easier to recover from
This created a lightweight HA model without requiring:
- BGP convergence
- Mesh synchronization
- Overlay routing complexity
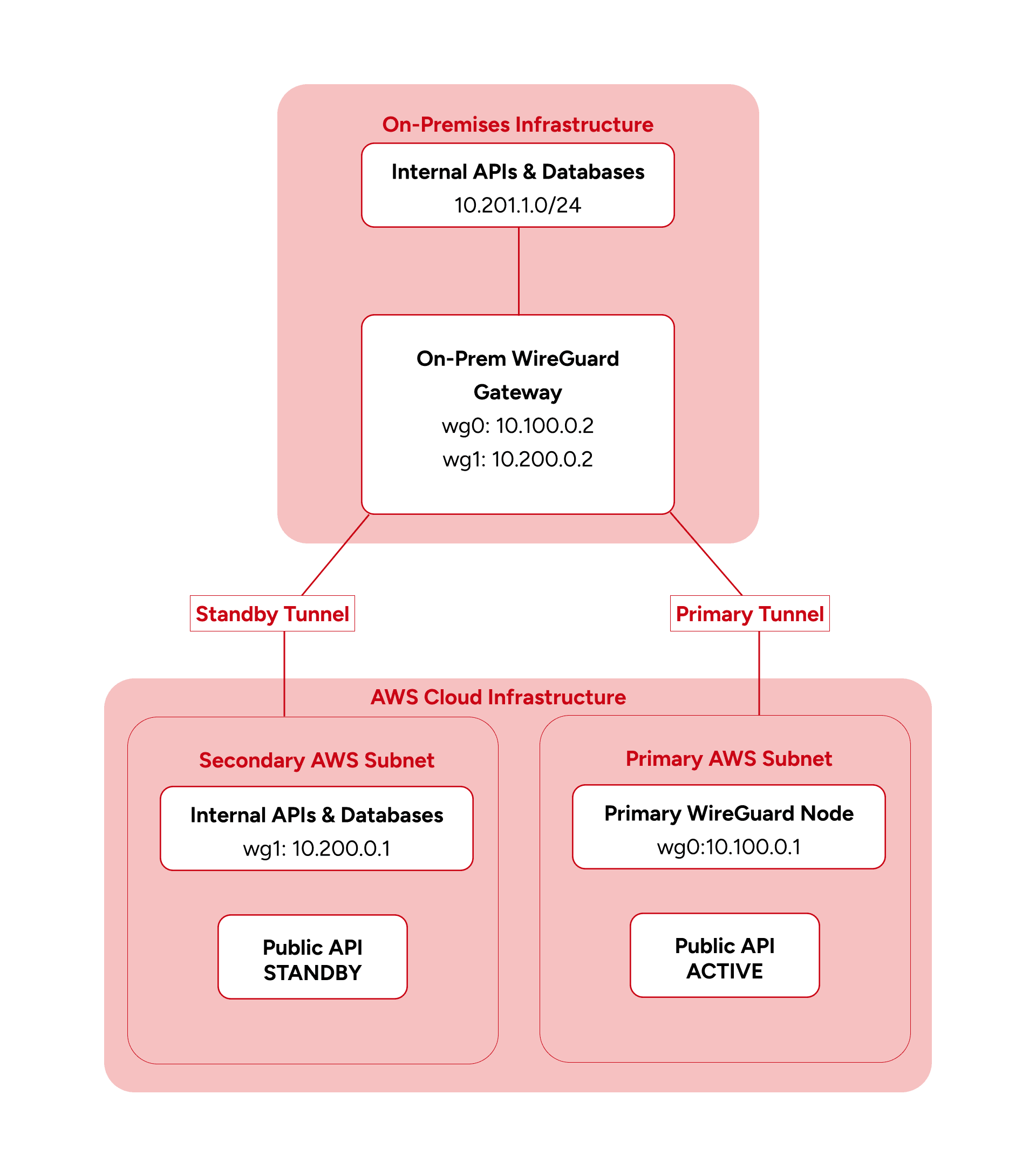
Why Subnet Isolation Became Critical
Each tunnel path owned an isolated subnet slice.
| Environment | Interface | Tunnel IP | Role |
|---|---|---|---|
| On-Premises | wg0 / wg1 | 10.100.0.2 / 10.200.0.2 | Core Plane |
| AWS Primary | wg0 | 10.100.0.1 | ACTIVE |
| AWS Secondary | wg1 | 10.200.0.1 | STANDBY |
Initially, the architecture experimented with less strict routing separation.
Operationally, this produced:
- Overlapping route ambiguity
- Inconsistent packet forwarding
- Difficult troubleshooting during failover testing
Subnet isolation dramatically simplified recovery behavior.
One operational lesson became very clear:
Simpler routing topologies fail in more understandable ways.
Separating VPN Edges from Backend Systems
Another important architectural decision was separating:
- VPN edge gateways
- Backend APIs
- Databases
- Public ingress layers
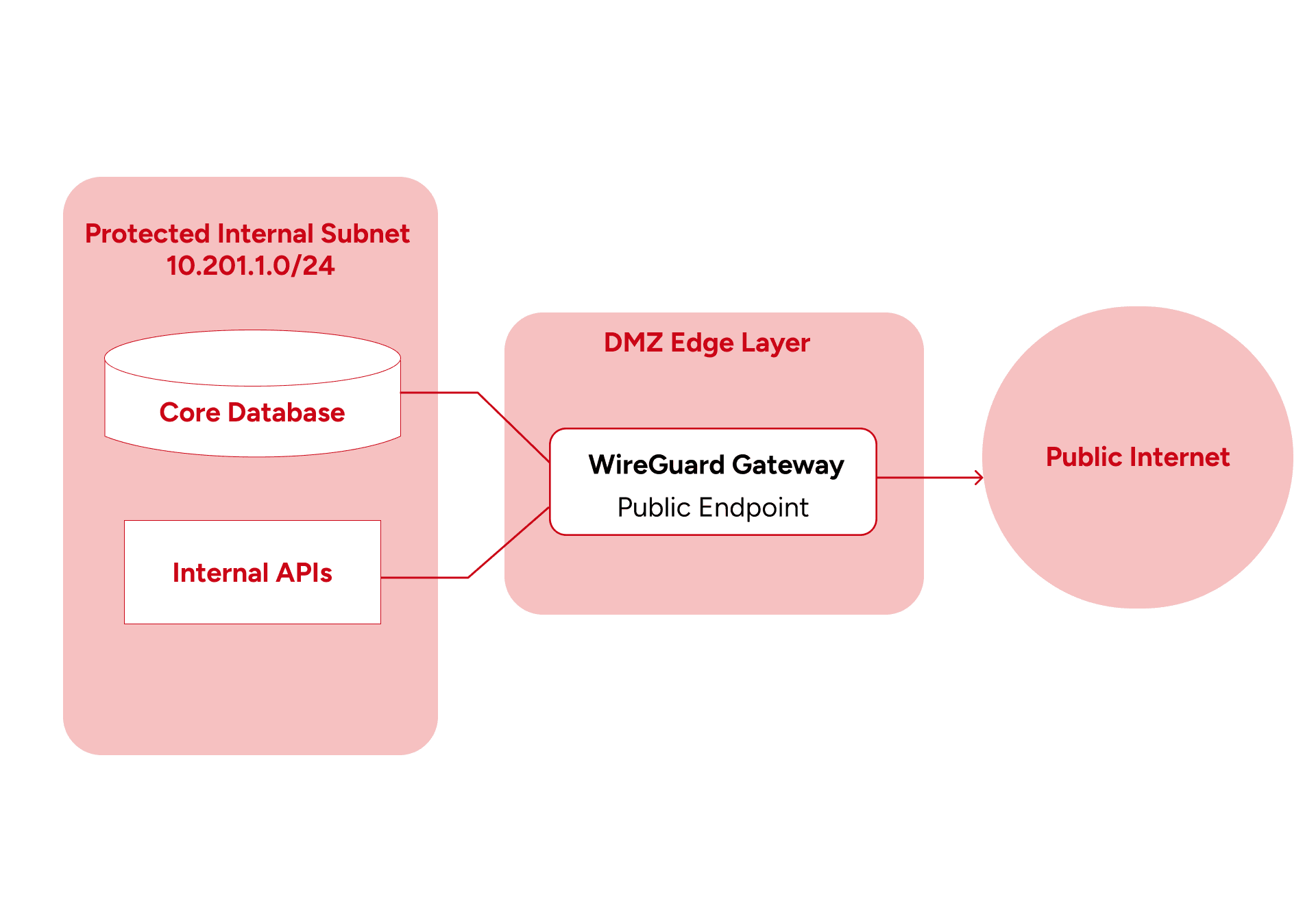
This separation reduced several operational risks:
- Routing recursion
- Asymmetric local forwarding
- Interface overlap
- Expanded blast radius
It also improved:
- Maintenance flexibility
- Backend isolation
- Operational scaling independence
The Biggest Monitoring Mistake We Initially Made
Early monitoring focused primarily on:
- Interface UP state
- WireGuard handshake timestamps
Initially, this appeared sufficient.
Operationally, it turned out to be dangerously misleading.
During testing, we observed tunnels remaining “healthy” from WireGuard’s perspective while real application traffic silently failed.
In several cases:
- Handshake timestamps continued updating
- Interfaces remained UP
- Packet forwarding had already degraded
This created:
- False-positive tunnel health
- Delayed failover
- Inconsistent operational visibility
One particularly difficult debugging session involved intermittent API failures where:
- ICMP occasionally worked
- Application traffic intermittently timed out
- Tunnel interfaces remained healthy
The root issue turned out to be partial packet-forwarding degradation rather than tunnel failure itself.
Evolving Toward Data-Plane Validation
The monitoring model evolved into three distinct validation layers.
| Validation Layer | Purpose |
|---|---|
| Interface Validation | Verify interface availability |
| Handshake Validation | Verify cryptographic synchronization |
| Data Plane Validation | Verify actual packet forwarding |
This ended up becoming one of the most important operational improvements in the system.
The final data-plane validation dramatically reduced:
- Silent tunnel degradation
- False-positive failovers
- Incorrect routing decisions
Production Health Validation Script
The monitoring flow validated:
- Interface state
- Handshake freshness
- Actual packet forwarding
That final packet-forwarding validation ended up becoming the most operationally valuable signal in the system.
Prometheus Observability Pipeline
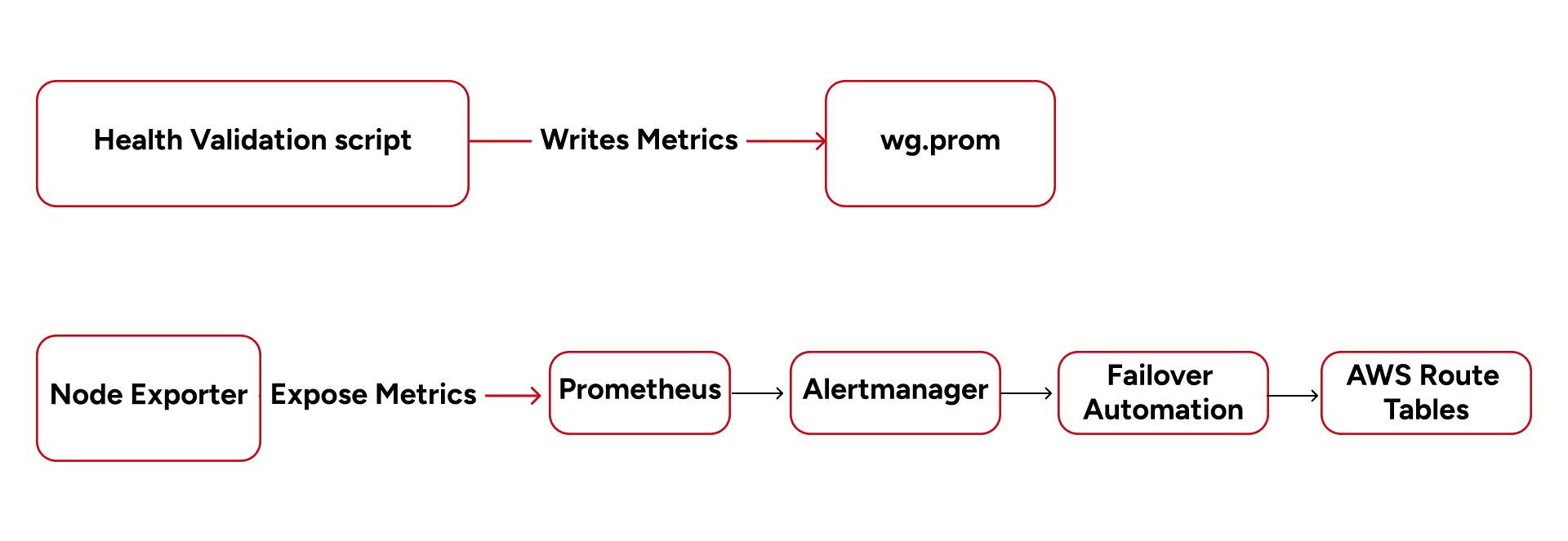
Infrastructure-Driven Failover
Instead of rebuilding tunnels or restarting applications during failures, failover occurred entirely through AWS Route Table updates.
When the primary tunnel degraded:
- Prometheus detected failure
- Alertmanager triggered automation
- Route targets were updated
- Traffic shifted to the standby WireGuard node

During testing:
- Primary degradation was typically detected within seconds
- Route updates remained operationally predictable
- Recovery became significantly more deterministic compared to earlier active-active experiments
One operational pattern became consistently clear:
Why This Architecture Worked Operationally
Operational Simplicity
The final design intentionally avoided:
- BGP convergence
- Overlay routing complexity
- Active-active synchronization
- Enterprise VPN orchestration
Everything relied primarily on:
- Linux routing
- Lightweight EC2 instances
- WireGuard
- Route-table automation
This significantly reduced operational overhead.
Better Failure Isolation
Separating:
- Tunnel paths
- Subnet ownership
- Route ownership
- Backend systems
made failures significantly easier to:
- Isolate
- Debug
- Recover from
Operationally, isolation improved confidence during incidents.
Observability Became More Valuable Than Redundancy Alone
One major lesson repeatedly surfaced during testing:
Redundant tunnels without packet-forwarding visibility still create operational risk.
The architecture became reliable not simply because of redundancy, but because degradation became observable.
That distinction mattered far more operationally than expected.
Cloud-Agnostic Portability
Because the architecture depended primarily on:
- WireGuard
- Linux-native routing
- Prometheus
- Infrastructure automation
the same design could be replicated across:
- AWS
- Azure
- Google Cloud
- Private cloud environments
- Bare-metal infrastructure
Final Thoughts
This architecture reinforced several operational principles repeatedly throughout testing.
First:
Simpler networking topologies are easier to recover from during real incidents.
Second:
Deterministic failover is often operationally more valuable than maximizing tunnel utilization.
And finally:
Observability matters more than redundancy alone.
Using:
- WireGuard
- Linux-native routing
- Prometheus observability
- AWS Route Table automation
It was possible to build:
- Resilient hybrid-cloud connectivity
- Predictable failover behavior
- Observable tunnel infrastructure
- Cloud-agnostic deployment patterns
Subscribe to Our Newsletter
Subscribe to RSS
Press & Media Hub RSS FeedRelated Articles.
More from the engineering frontline.
Dive deep into our research and insights on design, development, and the impact of various trends to businesses.

Jul 10, 2026
How We Built the Missing Bridge from Code to Figma

Jun 19, 2026
We Built a 114-Second AWS-to-Azure Failover. Here’s What We Learned

Jun 12, 2026
Cloud-Native and Cloud-Agnostic Are Not Ideologies; They Are Business-Stage Decisions

Jun 8, 2026
Geeklego: The Open-Source Design System Built to Work With AI

May 18, 2026
Your Vibe Code Has No Memory. DESIGN.md Fixes That.

May 14, 2026