Apr 20, 2023
Automated Grading of Interviews Using GPT-Powered AI
Find out how we utilized ChatGPT in our in-house automated hiring platform, topgeek, to simplify the process of grading interviews.
Author


Book a call
Table of Contents
Introduction
Grading interviews is time-sapping for companies, especially with the hiring process becoming intricate by the minute. In such a situation, Artificial Intelligence-powered hiring platforms are proving to be an effective solution. This article discusses one such AI-powered solution — topgeek coupled with ChatGPT.
The Problem Statement
Grading interviews manually is a subjective and time-consuming task. This is especially true for coding interviews since they require technical expertise.
An Automated evaluation can save time and ensure objectivity. We combined **topgeek**— our in-house hiring platform that conducts automated interviews and records the audio and video generated— ChatGPT, an AI technology created by OpenAI, to automate the evaluation process.
Architecture Overview
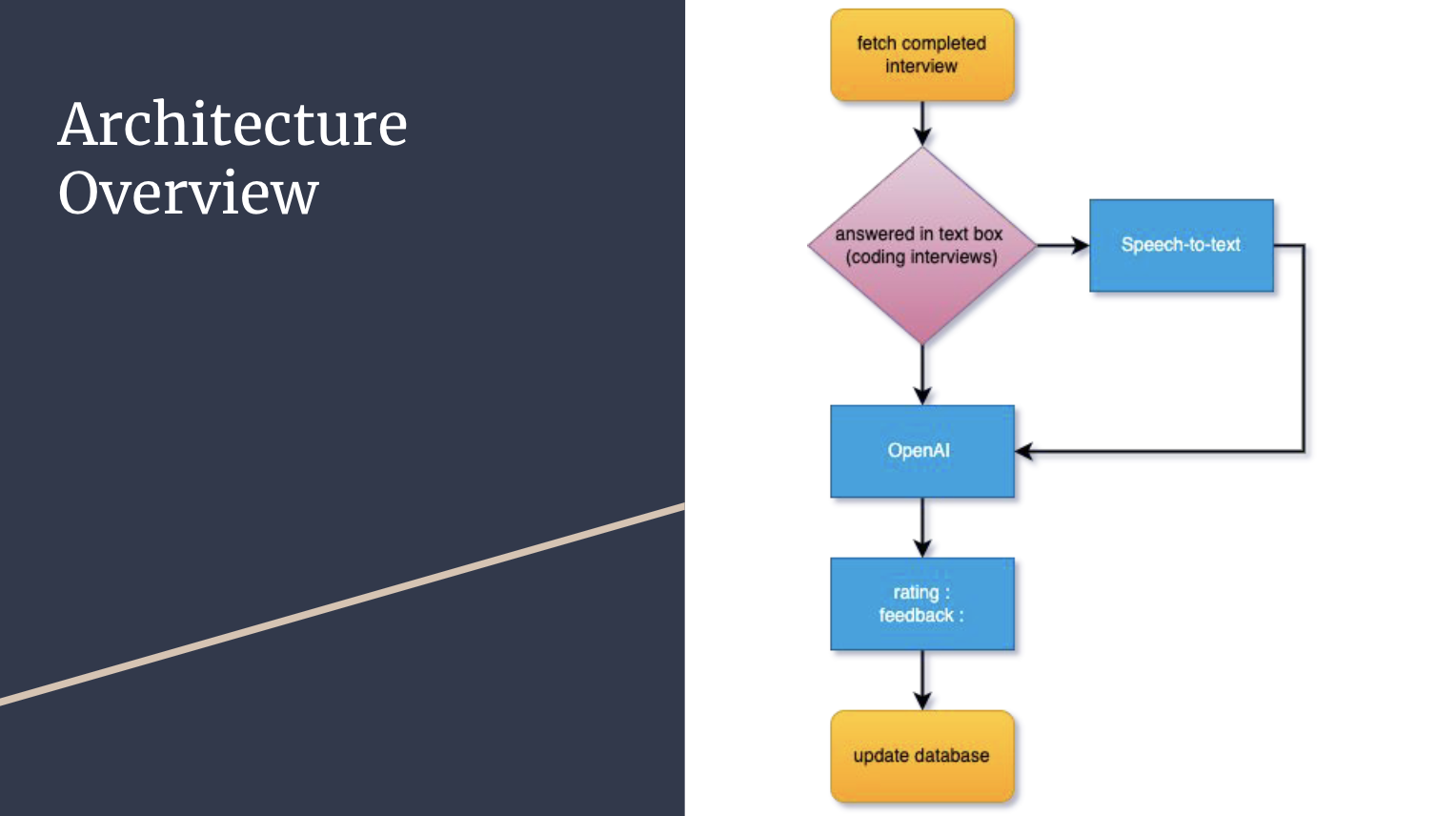
To automate the grading process, we used a combination of technologies:
- Deepgram API for speech-to-text transcription
- The OpenAI API for natural language processing
- GraphQL to interface with our database
Here is a process overview…
When a candidate completes an interview, the video and audio are recorded and stored in our topgeek database. We then retrieve the completed interviews, including the question asked, the answer given, and the audio and video recordings generated.
We used a GraphQL query to retrieve this data. For each interview, we extracted the audio recording as well as the written answer provided by the candidate in the text box. If the answer is given in speech, we used the Deepgram API to transcribe the candidate's speech to text. The transcribed text is then sent to the OpenAI API, which generates a rating and feedback based on the question and answer provided. Finally, we updated our database with the rating and feedback, automating the entire process.
Going Step by Step
The Data Retrieval Part
For retrieving the data, we used a GraphQL query which looks like this:
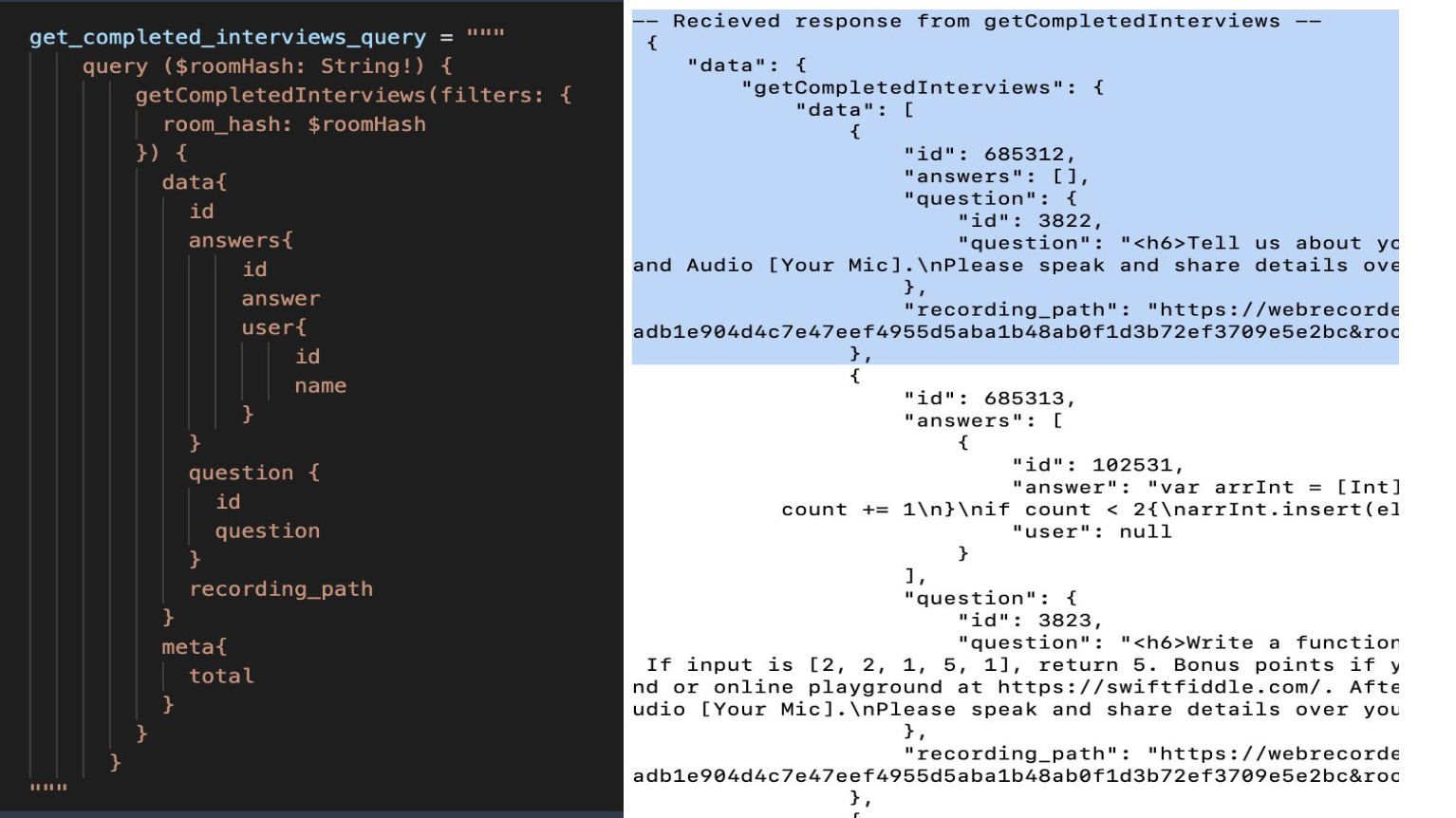
On the left-hand side, we attached a room hash to each interview. For each room hash, there are about 10 to 12 questions. On the right-hand side is the response. We get an answer, a question, a recording path, and a few IDs.
In the first question, highlighted in the image, we can see that the answer box [] is empty. This means that the candidate has answered in speech, and we need to convert it from speech to text. We chose Deepgram API for speech-to-text transcriptions as it is quite fast and works well with an Indian accent.
In the second answer, we can see that the answer is in code. OpenAI can be used to evaluate this code.
One important thing to note is that the transcriptions done for this evaluation process are saved in our database for future use and reference. We can see the saved information on the topgeek analytics page.
The Natural Language Processing Part
We used OpenAI to generate ratings and feedback.

We have a question retrieved from the GraphQL API and the answer in either a speech-to-text or code format. We then send a prompt “Please act as evaluator” and “Please rate this answer” between 0 to 10. Open AI acts as an evaluator once specified in a natural language format. We ask it to respond in the format “rating” and “comment” in JSON format.
The Code in Action
We can see the code we are sending to Open AI. We have specified a model_engine text-davinci-003. Open AI has multiple language models. The Davinci model is one of the best to use, as the answers given are primarily relevant and helpful. It is trained on various online books and articles and is famously known to accurately predict the next word depending on the last one.
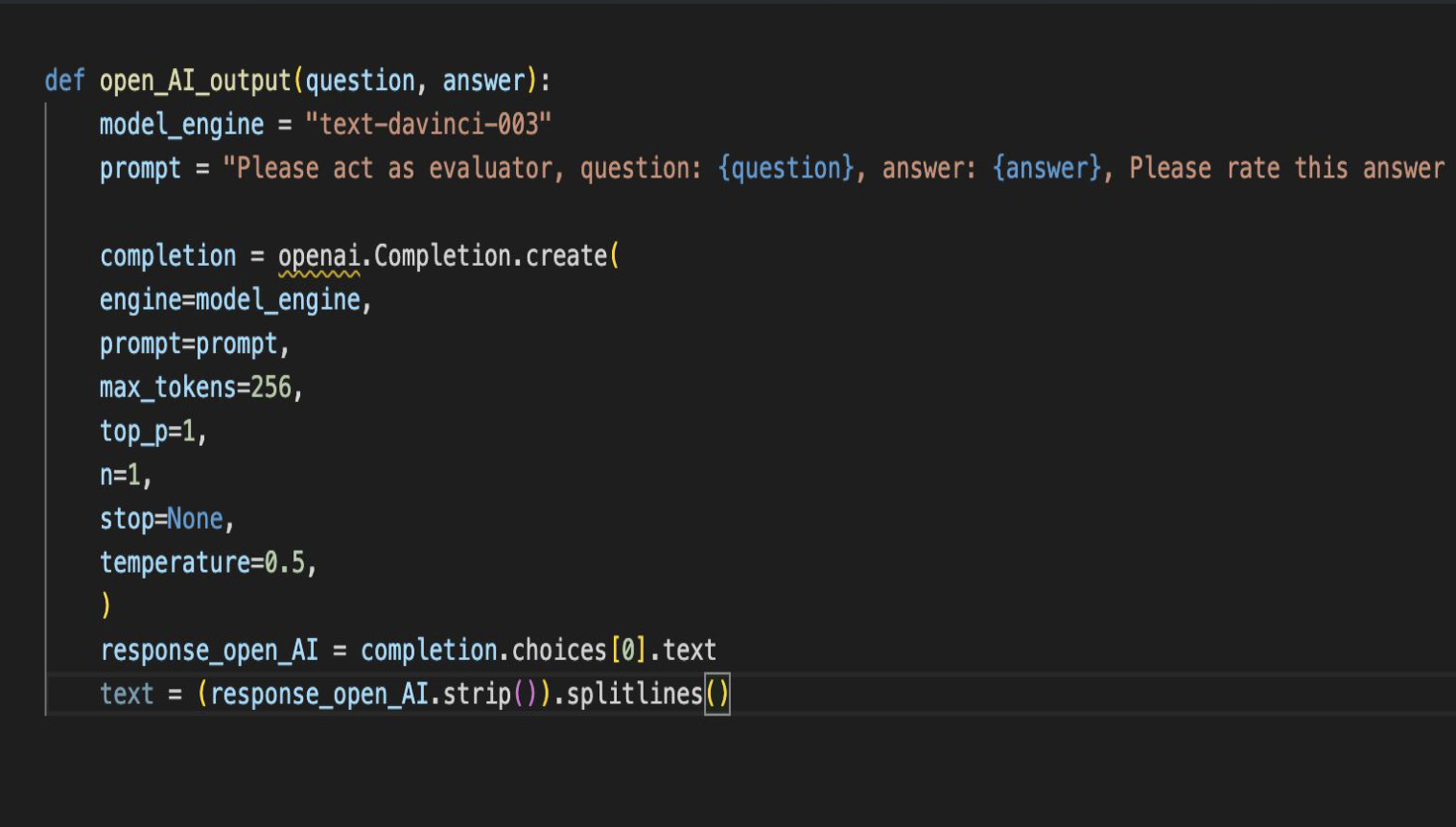
In the following code lines, we specify the engine, the prompt that acts as an evaluator and gives us the answer, and max_tokens which means the maximum length of solution we require. We use more parameters such as top_p, which means the highest probability of answers we want, stop=none, which means we do not want it to stop when a specific word is reached, and temperature, which is the randomness of the next prediction. We have currently set it to 0.5.
After this, we received the rating and feedback as requested.
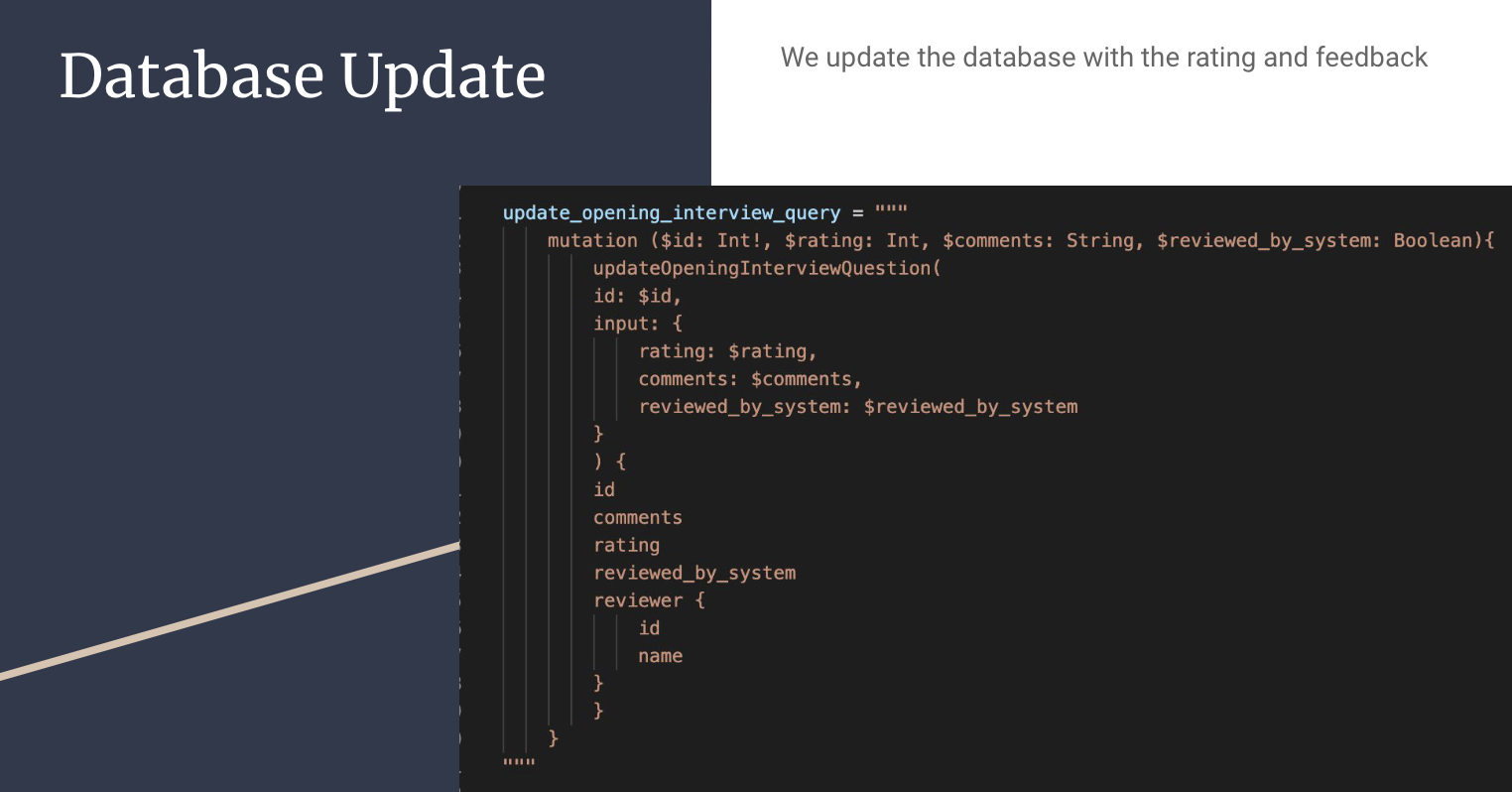
Database Update
Now that we have the rating and feedback, we need to update this information on our database. Here we use a GraphQL query called update_opening_interview to send back the rating and comments to the database.
Conclusion
Our system can accurately handle large volumes of coding interviews. However, we also learned that while OpenAI made things easier, manual evaluation is needed. For example, OpenAI sometimes provides ratings between 7 and 8.5 for most answers.
Changing the temperature, maximum tokens, and other hyperparameters did not help much in this case. Recently, Open AI launched ChatGPT’s API. We tested it, and it worked pretty well. We may be replacing OpenAI with ChatGPT AI following further testing.
If you have any questions or queries on the project, please feel free to reach out and schedule a call with us. CLICK HERE to book a slot.
Subscribe to Our Newsletter
Subscribe to RSS
Press & Media Hub RSS FeedRelated Articles.
More from the engineering frontline.
Dive deep into our research and insights on design, development, and the impact of various trends to businesses.

Jul 20, 2026
AI Operators in Insurance: Improving Customer Experience Through Intelligent Automation

Jul 17, 2026
From Compliance to Predictive Resilience: Building AI-Powered Supply Chain Risk Management Systems

Jul 10, 2026