Table of Contents
Developing a Stock Market App Backend
Author

Date
Book a call
Introduction
Stock market applications are residents of every phone’s home screen. Investors and traders range from experienced professionals to ordinary folks looking to benefit from the market. So, we decided to experiment and find out how to create a Stock Market app in the most efficient way possible.
The features of the app
- Stock trading
- Live stock price reflection
- Live order matching
- Stock line and candlestick graphs
- Stocks fundamental and Information
- Wish list of favorite stocks
This blog will explain in detail how the application’s backend was created with code snippets and examples.
Architecture of the Backend
From the drawing board, it was clear that it would be challenging to make the application scalable with a reliable architecture. Therefore, to reduce hiccups in development, we made the following checklist:
- The tech-stack should support a scalable and reliable backend even if the working of the app becomes extremely complex
- The service chosen for use as a message broker between the microservice and the main server should also work as pub/sub (publish/subscribe)
- The SQL DB would be chosen as a primary DB to store most of the data
- The Time series DB should be ideal to save all the executed orders
- The DB will be used to save all the matching engine orders. This will ensure fast restart and completion of pending orders, and the result will be a fast read/write speed.
Building the Backend — Tech-stacks and Services Used
1. Nest.js
Nest.js is the main framework to develop our backend, including our primary/main server and the microservice (Matching Engine).
2. Node.js
As Nest.js is a progressive Node.js framework, Node.js played a very vital role in the development of the project.
We developed a Matching Engine that would work as a microservice. It will communicate with the main server using a message broker, i.e. Redis.
4. Redis
Redis was used as a message broker between the primary server and microservices. It was also used for its pub/sub messaging paradigm for continuous communication between the main server and the matching engine.
5. PostgreSQL
This was our primary DB to store most of the data e.g. the users, stock details, etc.
6. Timescale DB
We chose it because it is built on top of Postgres and gives a fast read and write speed with timely data stored. It made it possible to keep several executed trades per second.
7. Cassandra
Cassandra is an open-source, distributed, NoSQL DB designed to handle a huge amount of data across many servers that provide high availability. Its high-performance and scalable database met our requirements for a DB to store the data of our matching engine.
8. Sockets
We used sockets for sending a continuous stream of data for the particular stocks to the client (users).
9. AWS
We used AWS's RDS service for Postgres and EC2 to host the server.
10. Docker
We have used Docker to containerize the main server and the matching engine.
For the app's codebase, we have used the mono-repo architecture.
Reasoning Behind the Tech-stacks Chosen
There are plenty of backend technologies, databases (both SQL and NoSQL), message brokers, time series databases, and many more in the market. So let's try to understand why we choose one over the other.
Nest.js over other Node.js Frameworks
Nest.js is a highly opinionated framework ( i.e. frameworks that have defined assumptions about architecture, best practices, and conventions). This provides us with strong guides on how to use tools and code in a certain way. That is the reason why Nest.js projects look and feel the same.
Why SQL as a primary DB?
Our data was going to be most of the daily users trading stocks. This meant keeping the data in a proper format with relations to the user, trades, orders, etc. So the choice we have left was to use the SQL database and with that, we could also do some complex queries in the DB and could make the project more scalable.
Why Timescale over other Time series DB
Since Postgres DB is our primary DB and Timescale DB is engineered up from PostgreSQL and packaged as a PostgreSQL extension. So it was an obvious choice for us to go with Timescale.
Why do we choose Redis over other Message Brokers?
We needed a message broker that we could use to communicate between the microservice and our main server. It should also provide the pub/sub functionality.
Need for Dockerizing
It was difficult to get all the configurations in different systems to run the application. That is the reason we chose to Containerize or Dockerize the project. This eliminated our worry about the dependencies and configurations every time we ran the project. The docker container takes care of it all.
Putting Everything Together
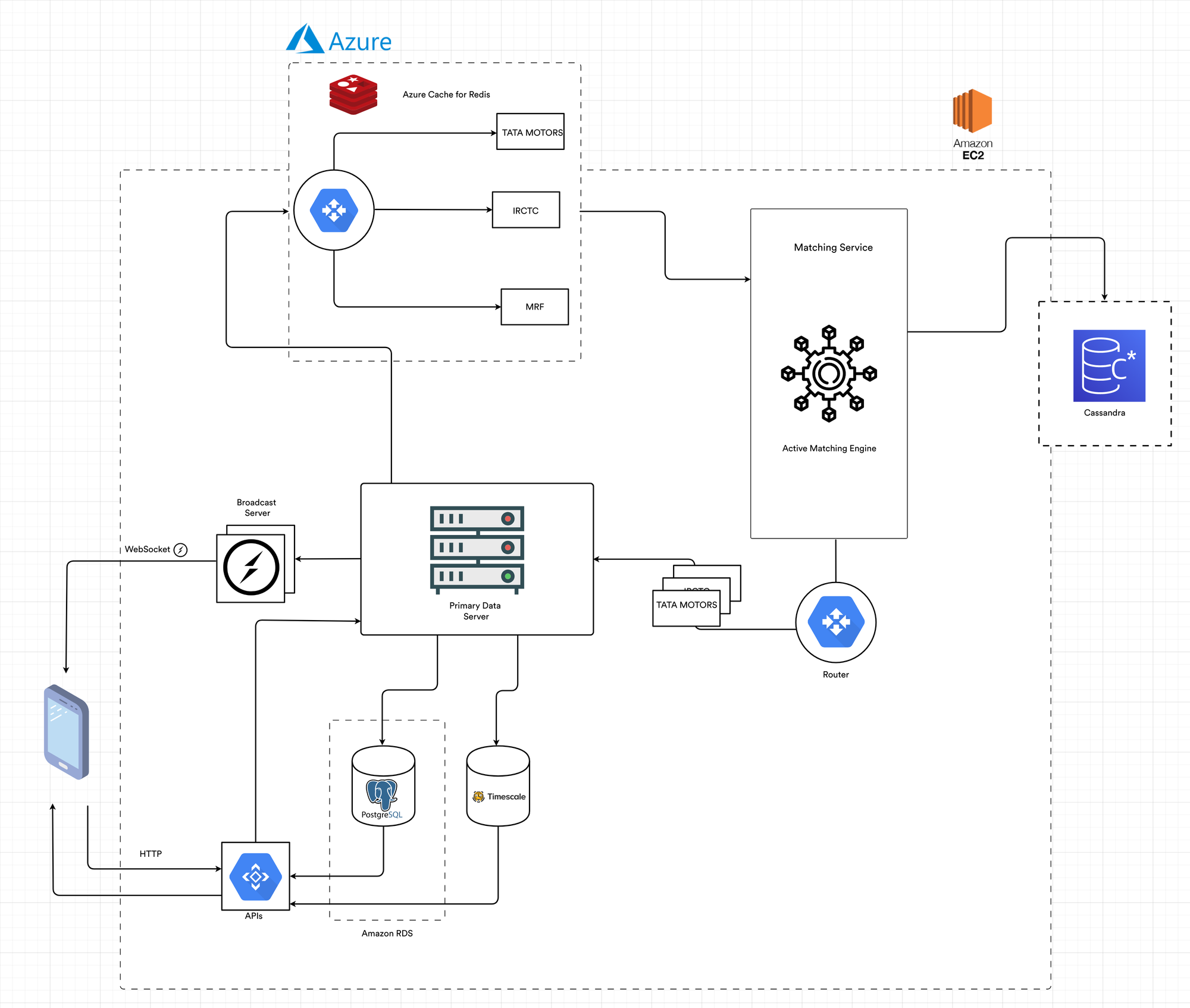
- We started with developing the matching engine. This step was challenging as there was no reference to check. But we successfully created one that could handle the workflow.
- Then we connected our primary server to the microservice with the help of Redis as a message broker. For each stock, the Redis would have a different queue. Whenever the server receives an order of a particular stock, it adds it to the queue of that stock, and the microservice will take the order from the same queue.
- Once the microservice receives an order, it saves it to Cassandra for future reference in case of failure.
- Once the matching engine can execute an order, it then sends it to the main server using Redis pub/sub. The primary server saves the executed trade in Timescale DB with the traded time as the primary key.
- The per-minute executed order information is then sent to the users through sockets for plotting the line graph and candlestick graph.
Here is a glimpse of the architecture that has been used in the backend.
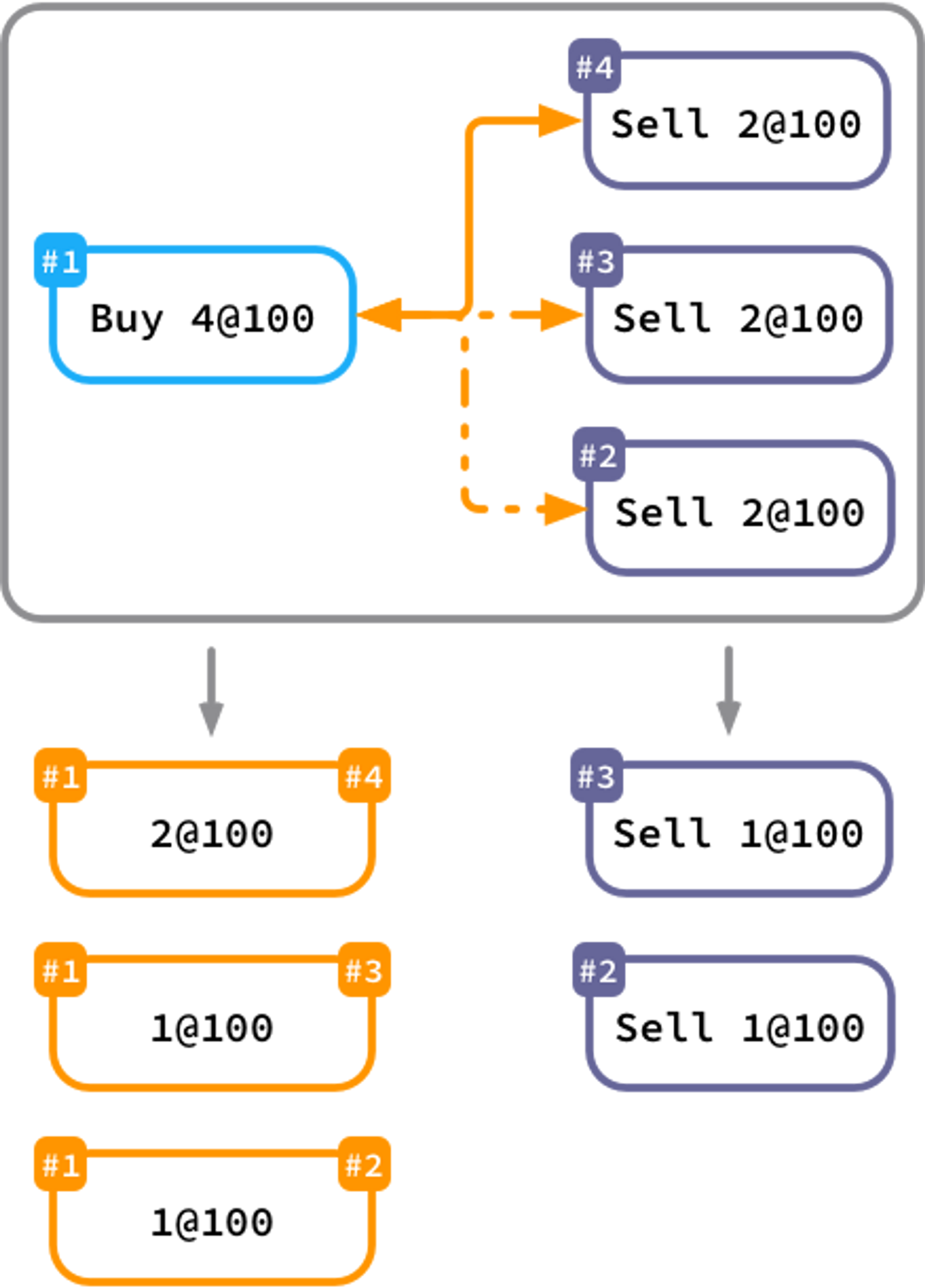
Project Backbone: The Matching Engine
The matching engine is an important component of the backend. It can work on different algorithms FIFO, Pro rata, etc. These algorithms set the priority of different users based on time, quantity, price, etc.
For example, let's say the engine gets a buy order for 500 shares at ₹50 per share, followed by another buy order of 200 shares at the same price. So, according to the FIFO algorithm (which we followed in the project), the total 500 shares buy orders will be matched to sell orders. After the 500 shares buy order is matched, the 200 shares buy order matching will start.
For a detailed explanation of how the Matching Engine works, check out our blog on the topic: Matching Engine for Stock Market App.
This article is part of the Research & Development work being done by Aman Chauhan and Rohit Prajapati.
Dive deep into our research and insights. In our articles and blogs, we explore topics on design, how it relates to development, and impact of various trends to businesses.


