Table of Contents
Introducing Tech Tonic — Our AI-powered Tech Stack Recommender
Author

Subject Matter Expert

Date

Book a call
This article breaks down Puja Agarwal and Sandeep Kumar Srivastava’s recent talk at our All Things AI Meetup. Their project Tech Tonic is based on OpenAI and focuses on unleashing the power of AI for personalized tech stack recommendations. They leveraged OpenAI's fine-tuning methodology to build this project.
GPT: The Architecture
What Is the Architecture of GPT and How Is It Built?
GPT stands for Generative Pre-trained Transformer, a model built by OpenAI in 2018. To date, four models of ChatGPT have been launched, with GPT-4 announced for release in March 2023.
We have utilized the GPT-3 model and trained it over our dataset to perform specific tasks. GPT can understand and manipulate human language, such as English, as a Natural Language Processing model. ChatGPT uses deep learning and transformer architecture, with the latter being the heart and soul of GPT. Mathematical techniques and deep learning have been implemented to improve the accuracy of results. ChatGPT has been trained semi-supervised, using over 45 terabytes of data from Wikipedia, Reddit, and literature books.
After unsupervised learning, ChatGPT was not yet able to produce human-understandable prompts. Thus, human trainers implemented supervised training to fine-tune the model for accuracy and enable it to generate human-understandable responses. ChatGPT was trained in two stages: pre-training in unsupervised mode and fine-tuning with required data in supervised mode to increase accuracy.
ChatGPT has numerous applications due to its ability to understand and manipulate human language.
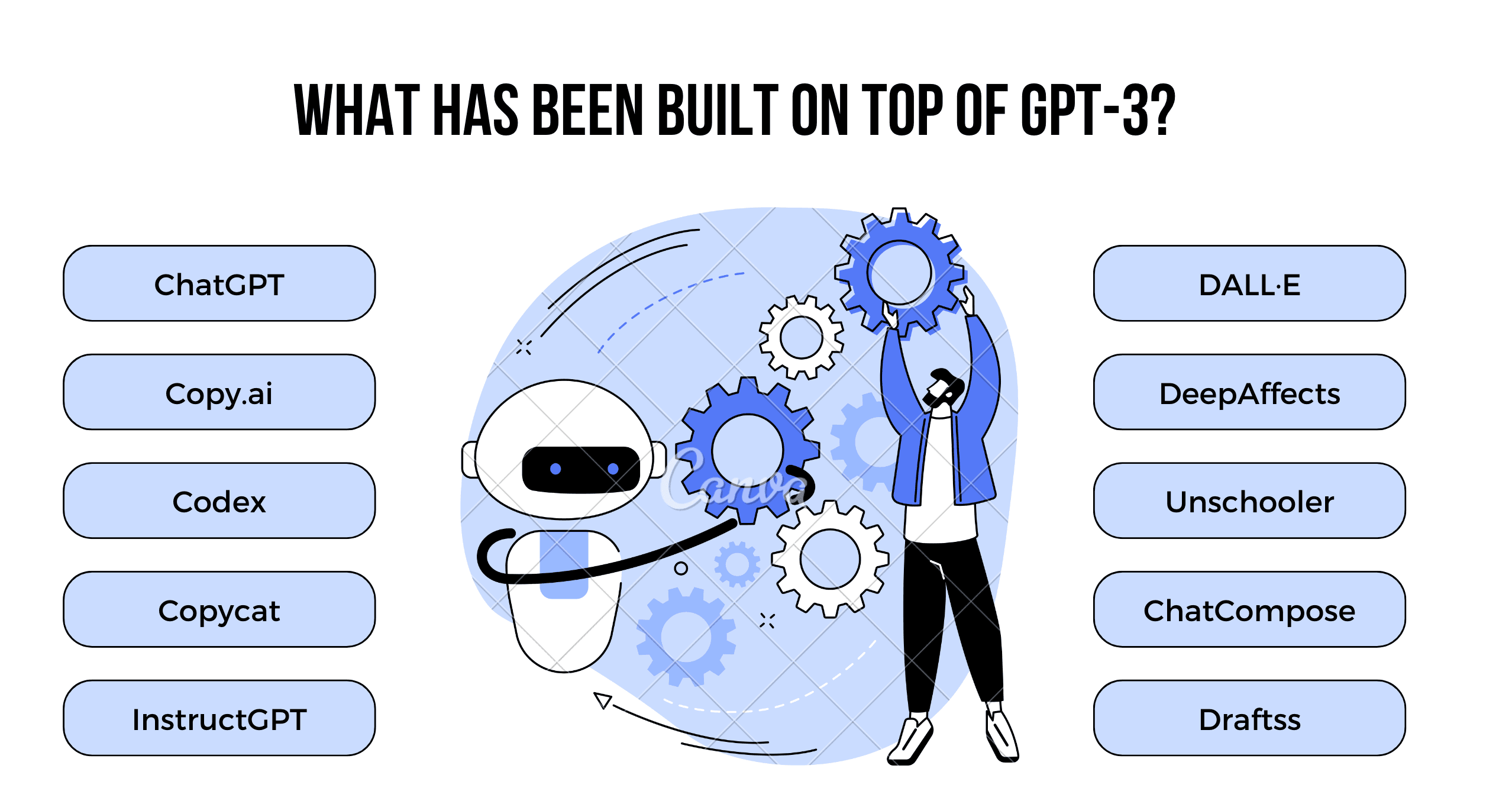
- ChatGPT is so ubiquitous in our day-to-day lives that it requires no introduction. Whether searching for a solution to a bug or asking it to write an email for our leave application, we are using it everywhere. Some of us have even integrated ChatGPT extensions into our Stack Overflow so that it helps us to find and solve problems.
- Many robust systems have already been built on GPT-3, including Codex. GitHub powers Codex and is specially trained to provide coding and customized bug solutions.
- Another notable system is DALL-E.
- One of our favorites is Unschooler. This tool helps you find all the necessary information when researching a topic or preparing an assignment.
Building ChatGPT on Top of GPT
ChatGPT was trained in two phases: pre-training and fine-tuning. During pre-training, it was taught about linguistics and the English language in order to understand human speech. For fine-tuning, structured data was required. While building ChatGPT, engineers discovered many flaws and used reinforcement learning from human feedback to improve its accuracy. They manually tested ChatGPT and prepared structured data based on the results, which was then used to further train ChatGPT and increase its accuracy.
Natural Language Processing (NLP)
Natural Language Processing (NLP) is a subfield of machine learning that focuses on the interaction between computers and human language. The goal is to make this interaction as smooth as possible, allowing the machine language model to directly understand what the human is trying to say and provide output that is easily understood by humans. With NLP, computers can perform language processing, sentiment analysis, and voice assistance.
We can see the application of NLP in many voice assistants when we call customer service. For instance, if you are calling to request a refund from an E-commerce company, a voice assistant will talk to you, collect your details, and cater to you in the same way a human would. This is one of the best implementations of NLP in chatbots and voice assistants, as it allows for seamless interaction between humans and machines.
Supervised and Unsupervised Learning
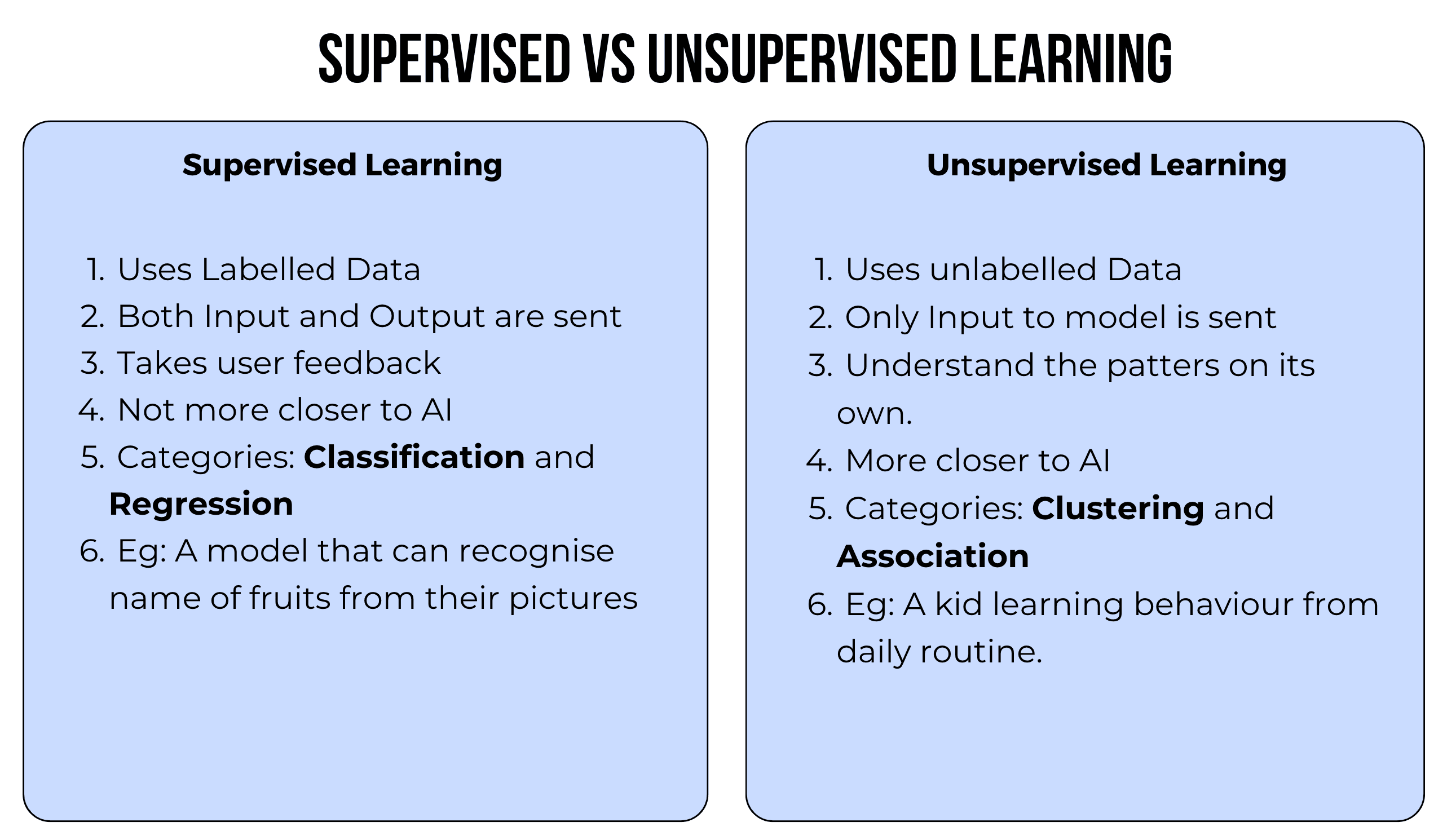
So, what are the differences between supervised and unsupervised learning? Let’s find out.
In supervised learning, we use labeled data to train the model. This means that we provide the model with data along with additional information regarding that data. For example, if we want to build a machine-learning model that can recognize the name of a fruit by seeing its picture, we cannot directly feed the images to the model. Instead, we need to feed labeled data to the model. For example, we need to feed the picture of an apple, along with the name of the fruit i.e. apple, so that whenever an apple is presented, the AI model knows that it is an apple.
In unsupervised learning, we feed the model with unlabeled data and allow the model to understand patterns and relationships between the data. In supervised learning, we feed both input and output to the model so that it can give the output based on the input that is being fed to it.
Supervised learning is said not to be closer to AI because it involves more data feeding. In contrast, unsupervised learning is said to be closer to AI. There are two categories of supervised learning: classification and regression. In unsupervised learning, there are two categories: clustering and association. Clustering and association are widely used in data mining.
A great example of unsupervised learning is a kid who is learning behavior from a daily routine. A kid who used to cry while going to school in nursery class does not cry anymore while going to school when he is in the third class. He knows that going to school is a part of his daily routine, and he has to follow it. Similarly, an AI model follows the same process while learning from feedback provided day to day during unsupervised learning.
Reinforcement Learning

Let's start with an example. When using ChatGPT, you might encounter a prompt as above that asks whether a generated response was better or worse. Suppose you click on "Better." ChatGPT will then adapt a self-teaching system to generate similar responses in the future. If you click on "Worse," ChatGPT will understand that the generated response was incorrect and will not produce the same response for similar inputs in the future. If you click "Same," ChatGPT understands there was no improvement and will not make any changes. The reinforcement learning model focuses on maximizing rewards by providing a correct or closer-to-correct output.
In essence, reinforcement learning is about increasing the productivity or accuracy of a model.
What is Fine Tuning?
Fine-tuning is a process of adapting a pre-trained machine learning model to perform specific tasks. Simply, it involves taking a pre-trained model like GPT-3 and training it on a specific dataset to perform a particular activity. This involves adjusting the model's parameters based on the new dataset being fed.
We used fine-tuning by training GPT-3 on our dataset, enabling it to recommend tech stacks to users seeking information. This saved us time, as we could utilize GPT-3 instead of creating a model from scratch.
However, fine-tuning has limitations. It is effective only for tasks with limited labeled data and does not work with unlabeled data. Additionally, it requires more computational resources and follows supervised learning.
How We Used Fine Tuning
We provided labeled data to the GPT-3 model and fine-tuned it through multiple iterations. Initially, the model generated random English sentences with less than 10% accuracy when we tested it. It simply generated whatever English sentence it fetched without considering the context. To improve its accuracy, we increased the size of the dataset and continued fine-tuning it through two to three iterations. As a result, its productivity increased, and it started generating more accurate results. We evaluated its performance on OpenAI's playground, where we tested the model by providing prompts and conducting various tests.
Differences between Embedding and Fine-tuning
Since fine-tuning only works with supervised learning, what is the alternative?
One alternative is to train a pre-trained model using unsupervised learning using embedding. Embedding represents data as vectors in multidimensional space and follows unsupervised learning. Embedding models can capture patterns in data similarly to unsupervised learning. However, one drawback of embedding is that separate search techniques need to be implemented, which are based on deep learning and mathematical computations. This makes it a bit difficult to implement search techniques.
In contrast, fine-tuning directly follows supervised learning, and data is fed directly to it. The image above shows the data we fed to our model. We fine-tuned it with task-specific adaptation.
If we didn't have this data, we would use embedding so that we could feed unsupervised data to it. Embedding is used when large, unlabelled data is present, while fine-tuning is used when task-specific adaptation is required. With embedding, you can create sentiment analysis systems or recommendation systems, while fine-tuning is more commonly used in question-answering tasks.
So What is Tech Tonic?
Tech Tonic is a tech stack recommender designed to simplify the process of selecting the best tech stack for a particular use case. Many project managers struggle to identify the optimal tech stack for their projects due to time constraints and a lack of necessary skills among their development teams.
Tech Tonic addresses this issue by providing personalized recommendations based on specific project requirements. It utilizes OpenAI's fine-tuned model and may incorporate reinforcement learning in the future.
The tool considers a variety of factors, including team size, project duration, project size, project name, and the skill sets of the development team. By analyzing this data, Tech Tonic is able to suggest the most suitable tech stack.
Currently in development mode, Tech Tonic has an accuracy rate of 60-65%. However, the implementation of reinforcement learning will enable the tool to learn from feedback, allowing for continuous improvement and increased accuracy.
Key Features of Tech Tonic
A quick look at the key features:
- Fine-Tuned Model: We use a fine-tuned model that provides inputs based on the context you provide.
- Project Information: It collects a lot of user information to provide tailored results.
- Streamlined Output: The output is a one-line, clean and understandable form, allowing you to quickly determine the tech stack to use and save time and resources.
- Accuracy: The accuracy of our model is about 65%.
- User-friendly Interface: The user-friendly interface makes it easy to input your data.
- Recommendations: Tech Tonic also provides documentation links, GitHub projects on the same tech stack, and Udemy videos that you can refer to and get started building your project.
- Future-proofing: We're also implementing reinforcement learning to ensure future-proofing.
How Does Tech Tonic Work?
Let us break down the basics:
- We used OpenAI fine-tuning to define the model system.
- We also used a front-end integration.
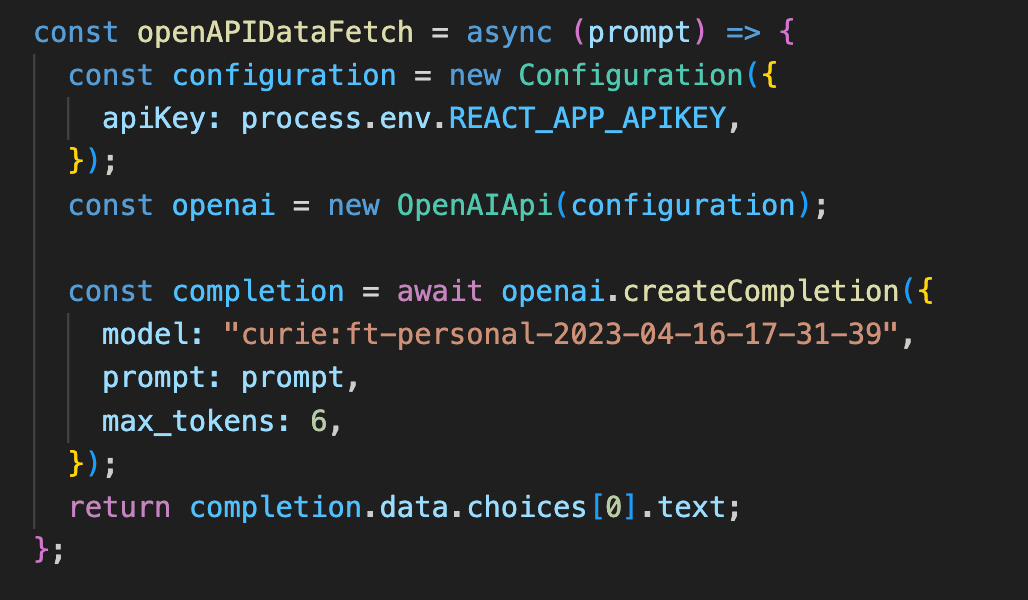
We have used OpenAI NPM Package, where we directly get the API key from OpenAI and used it in our open model. In the image above, you can see the model name and the question we are asking or the prompt. max_tokens: 6 refers to the number of words that we have to receive.
- GPT-3.5 Turbo Integration helps us get any other external resources for our tech stack recommender.
Conclusion
Tech Tonic is an AI-powered tool designed to provide personalized tech stack recommendations based on specific project requirements. It utilizes OpenAI's fine-tuned model and incorporates reinforcement learning for continuous improvement and increased accuracy. The tool considers a variety of factors, including team size, project duration, project size, project name, and the skill sets of the development team to suggest the most suitable tech stack. With its user-friendly interface, streamlined output, and future-proofing implementation, Tech Tonic simplifies the process of selecting the best tech stack for a particular use case.
For a detailed project demo, check out this video.
Check out the entire talk here ⬇️
Dive deep into our research and insights. In our articles and blogs, we explore topics on design, how it relates to development, and impact of various trends to businesses.


