Oct 23, 2023
How to Train YOLOv3 to Detect Custom Objects? (Demo Video Included)
This comprehensive tutorial guides you through the process using YOLOv3 architecture, providing a powerful tool for accurate and efficient object recognition in images or videos.
Author


Book a call
Table of Contents
This is a step-by-step tutorial on training object detection models on a custom dataset.

What is Object Detection?
Object Detection (OD) is a computer vision technique that allows us to identify and locate objects in digital images/videos. It is basically a combination of localizing objects in images/videos and classifying them into respective classes. Object detection is used extensively in many interesting areas of work and study, such as
- Security
- ANPR(automatic number plate detection)
- Crowd counting
- Self-driving cars
- Anomaly detection
- Medical field
Object detection is commonly confused with image recognition. Image recognition assigns a label to an image. On the other hand object detection draws a box around the recognized object. The model predicts where each object is and what label should be applied. In that way, object detection provides more information about an image than recognition.

Here, we are going to use YOLO family of object detectors, specifically YOLOv3.
What is YOLO?
YOLO (You Only Look Once) is a state-of-the-art, real-time object detection system. Since its inception, it has evolved from v1 to YOLOvX to this date. To Know more about YOLO versions, you can refer here. We are going to focus on yolov3 for this tutorial.
- For the purpose of this tutorial, we will be using Google Colab to train on a sample dataset we have provided. Follow the steps below.
Required libraries :
- Python 3.5 or higher
- Tensorflow
- OpenCV
This tutorial is divided into 3 main steps:
- Collecting and preparing custom data
- Training
- Testing
Let us get started. Notebook for the code is provided here, you can follow along with the code. We will now look into the steps needed.
Step 1 : Collecting and Preparing Custom Data
Gathering the data
For custom object detection, you need some data to train and test the model. You can either download an already labeled public data set or create your own data set.
Some great sites to get public data sets are:
To create your own dataset, you can download images from the internet or take pictures yourself. You can decide the number of classes you want you want to train on. Here, we are training our model for one class - butterfly. For this, I have created a sample dataset by downloading 100 images of a butterfly from here. The entire dataset has ten categories and 832 images, but for now, we are using 100 images for creating a sample dataset. Next, we need to annotate these images.
Note : If you are using already labeled dataset, make sure to convert them in yolo format and you can skip the annotation step. For this, take a look here. YOLO format is explained below.
Annotation
Next, we need to annotate these images, there are many tools available for this:
There is no single standard format when it comes to image annotation. Some of the commonly used annotation formats are COCO, YOLO, and Pascal VOC. For getting image annotations in YOLO format, https://github.com/tzutalin/labelImg is preferred as it is easy to install and use. For installing, check out https://github.com/tzutalin/labelImg. If you choose to use this tool for annotations, make sure to change the output format to YOLO.
YOLO Format
In YOLO labeling format, a .txt file with the same name is created for each image file in the same directory. Each .txt file contains the annotations for the corresponding image file, that is, object class, object coordinates, height, and width. For each object, a new line is created. Below is an example of annotation in YOLO format :

You can save all the annotations fine in the same folder as the images and name the folder images.
Step 2 : Prerequisites for Training
1. Mount Drive and Get Images Folder
For training, we are going to take advantage of the free GPU offered by Google Colab.
- Create a new folder in Google Drive called
yolo_custom_training - Zip the
imagesfolder and upload the zipped file to the empty directoryyolo_custom_training, on the drive - Go to Google Colab, create a new notebook, and name it
YOLO_custom_training_notebook - Mount Google Drive and give permission when asked to access Google Drive
- Unzip the
imagesfolder
Next, we are going to install dependencies.
2. Clone the Darknet
You Only Look Once (YOLO) utilizes darknet for real-time object detection, ImageNet classification, recurrent neural networks (RNNs), and many others.
Darknet is an open-source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation. Advanced implementations of deep neural networks can be done using Darknet.
First, we need to clone the repo and then compile it. Before compiling, in the case of GPU, you need to make some changes in Makefile to utilize GPU acceleration. You need to change GPU = 1, CUDNN =1, OPENCV = 1. If using CPU, leave it at 0. Since we are using Google Colab, which gives us free access to GPU, we are going to make these changes.
- Clone the Darknet
- Compile Darknet using NVIDIA GPU, make changes in makefile, GPU,CUDNN,OPENCV=1
3. Configure Darknet Network for Training YOLO V3 - Update CFG File for Training
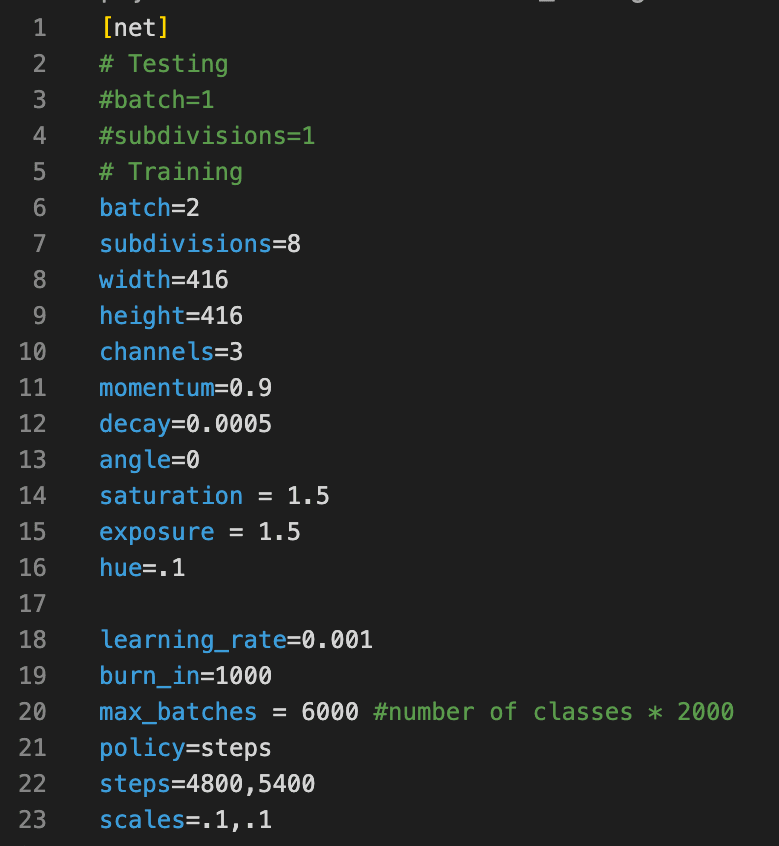
Once you have the Darknet folder, you need to make some changes in the CFG file which contains details about your training and testing like batch size, hyperparameters etc.
- For training, we will make a copy of the CFG file and make required changes
- Change line batch to
[batch=2] - Change line subdivisions to
[subdivisions=8] - Change line max_batches to (
classes*2000, but not less than the number of training images, and not less than 6000), i.e.[max_batches=6000]if you train for three classes - Change line steps to 80% and 90% of max_batches. For example,
[steps=4800,5400] - For training, comment batch and subdivision for testing i.e. lines 3 and 4
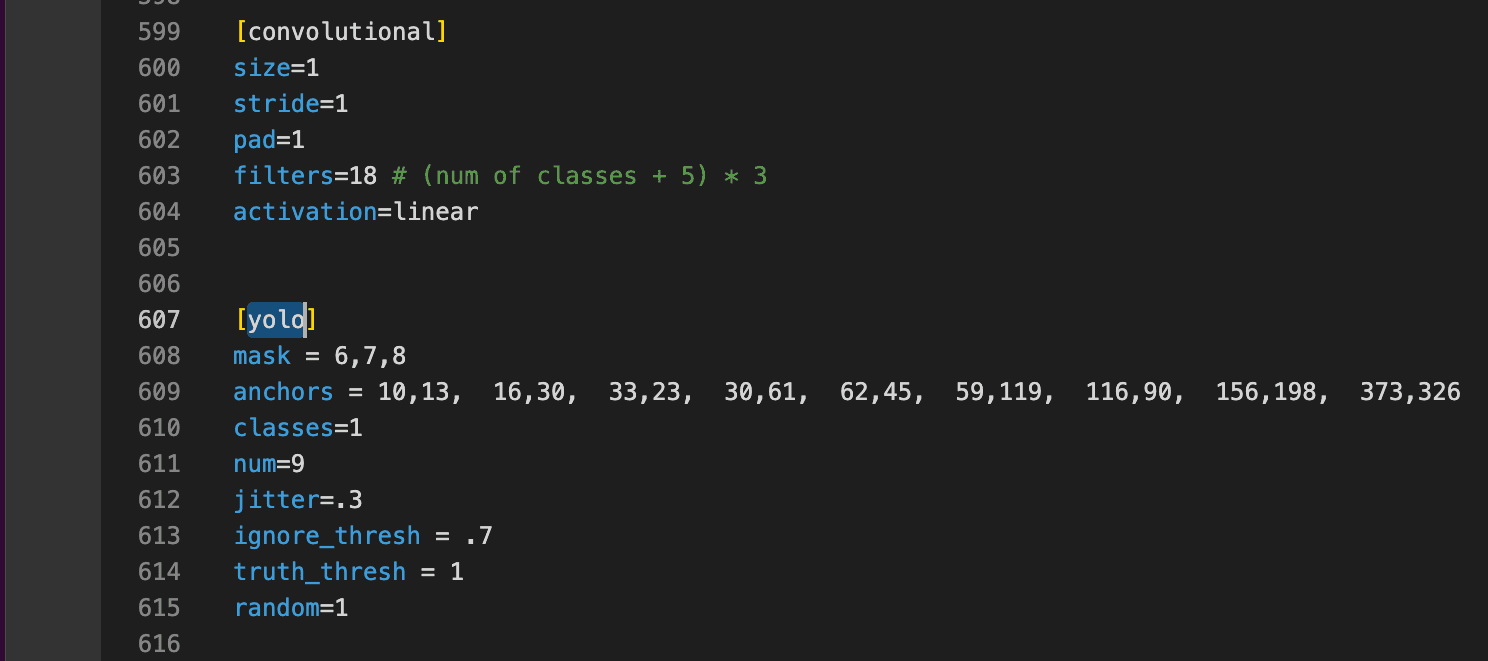
- Change line
classes=1to your number of objects in each of 3[yolo]layers - Change [
filters=255] to filters=(classes + 5)x3 in the 3[convolutional]before each[yolo]layer, keep in mind that it only has to be the last[convolutional]before each of the[yolo]layers. So ifclasses=1then should befilters=18. Ifclasses=2then writefilters=21
- To make changes in CFG file, you can either download the file, make the following changes on local and upload it on drive at
/content/gdrive/MyDrive/yolo_custom_training/cfg/yolov3_custom_training.cfg,
or in Colab, we can use the following command line commands:
- For training , we need to comment the testing batch size and subdivision and similarly while testing, we need to comment training parameters.
4. Setup the Data Config Files
path_data.data contains the details of the dataset you want to train your model on. The file looks like this. We will create the required files one by one.

train,test, andval: Locations of train, test, and validation imagesclasses: Number of classes in the datasetnames: path of names of the classes in the dataset(classes.names file). The index of the classes in this list would be used as an identifier for the class names in the codebackup: Folder path in which the weights will be saved after training
Let us create these files.
- Create classes.names files
Create classes.names files that contains objects names - each in new line. We can create one using classes.txt file created during annotations file.
or create it manually.

- Create
path_data.data
- Create backup folder in
/content/gdrive/MyDrive/yolo_custom_training/images/
- Create file train.txt and test.txt
Create file train.txt and test.txt in directory /content/gdrive/MyDrive/yolo_custom_training/images\ , with filenames of your images, each filename in new line, with path relative to darknet.exe, for example containing:
5. Weights
We are going to use transfer learning here. For this, we are going to use a pre-trained model called darknet53.conv.74, trained in various classes. Now, you must create a new folder called custom_weights and place the pre-trained model in it.
6. Start the Training
Start training by using the command line:
Step 3 : Testing the Model
After training, the weights will be saved in backup folder that we created earlier. We will be using yolov3_custom_last.weights for testing. You can either download the weights to your local and continue from there, or use Colab.
- Changes in the CFG file
- For testing, we need to comment on the training parameters in .cfg file by commenting lines 6 and 7 and uncommenting lines 3 and 4.
- Load the model and classes and weights
- We first read the network model saved in Darknet model files using Opencv’s readNetFromDarknet() function. It requires two parameters, path to the .cfg file and path to the .weights file with the learned network.
- Read the input image and process it for darknet
- then, we read the input image and its height and width, on which we will make the prediction.
- Now we have the image in RGB format that has a shape of width*height*channels, but YOLO Net takes images in a different format, so we need to convert it into the required format before feeding it to the network. For this, we use cv2.dnn.blobFromImage(). We are going to feed this blob to our YOLO network.
- Determine only the output layer names that we need from YOLO.
- Predict and draw the predicted boxes.
Draw a box around the object.
- You will get the results image with bounding box saved as
output.pngin/content/gdrive/MyDrive/yolo_custom_training/output.png
Here is the entire code for prediction :
Conclusion
This comprehensive tutorial offers a detailed and accessible guide to training custom object detection models using the YOLOv3 architecture. By leveraging the state-of-the-art YOLOv3, you can effectively identify and locate objects in images or videos. By following the steps discussed, you can harness the potential of custom object detection models tailored to their specific datasets and applications, ushering in a new era of accuracy and efficiency in object recognition technology.
Subscribe to Our Newsletter
Subscribe to RSS
Press & Media Hub RSS FeedRelated Articles.
More from the engineering frontline.
Dive deep into our research and insights on design, development, and the impact of various trends to businesses.

Jul 22, 2026
Why Healthcare Organizations Are Moving Beyond Telehealth Toward AI-Driven Care Systems

Jul 20, 2026
AI Operators in Insurance: Improving Customer Experience Through Intelligent Automation

Jul 17, 2026