Oct 20, 2023
How to Build a Basic Speech Recognition Network with Tensorflow (Demo Video Included)
Master speech recognition with TensorFlow and learn to build a basic network for recognizing speech commands. Dive into ASR techniques with this step-by-step guide.
Author


Book a call
Table of Contents
Introduction
This tutorial will show you how to build a basic speech recognition network that recognizes simple speech commands. Speech recognition is a subfield of computer science and linguistics that identifies spoken words and converts them into text.
A Basic Understanding of the Techniques Involved
When speech is recorded using a voice recording device like a microphone, it converts physical sound to electrical energy. Then, using an analog-to-digital converter, this is converted to digital data, which can be fed to a neural network or hidden Markov model to convert them to text.
We are going to train such a neural network here, which, after training, will be able to recognize small speech commands.
Speech recognition is also known as:
- Automatic Speech Recognition (ASR)
- Computer Speech Recognition
- Speech to Text (STT)
The steps involved are:
- Import required libraries
- Download dataset
- Data Exploration and Visualization
- Preprocessing
- Training
- Testing
Here is a colab notebook with all of the codes if you want to follow along.
Let us start the implementation.
Step 1: Import Necessary Modules and Dependencies
Step 2: Download the Dataset
Download and extract the mini_speech_commands.zip, file containing the smaller Speech Commands datasets.
The dataset's audio clips are stored in eight folders corresponding to each speech command: no, yes,down,go,left, up,right,and stop.
Dataset: TensorFlow recently released the Speech Commands Datasets. It includes 65,000 one-second long utterances of 30 short words by thousands of different people. We will be working with a smaller version of the Speech Commands dataset called mini speech command datasets.
Download the mini Speech Commands dataset and unzip it.
The dataset's audio clips are stored in eight folders corresponding to each speech command: no yes down go left up right and stop
Now that we have the dataset, let us understand and visualize it.
Step 3: Data Exploration and Visualization
Data Exploration and Visualization is an approach that helps us understand what's in a dataset and the characteristics of the dataset. Let us visualize the audio signal in the time series domain.
Here is what the audio looks in a waveform.
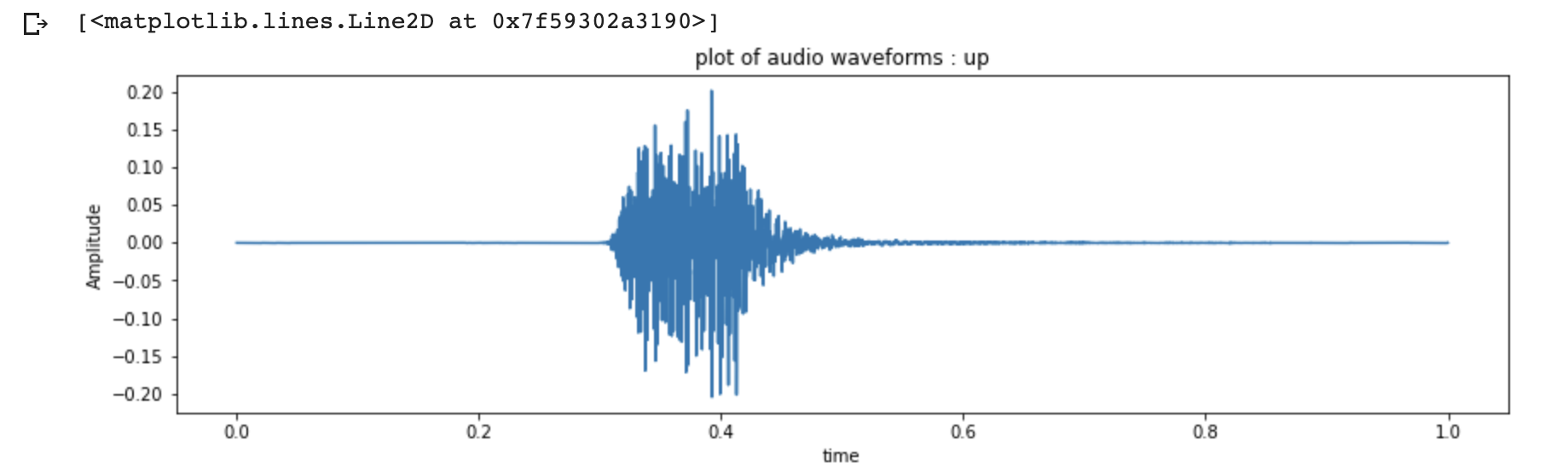
To listen to the above command up :
Check the list of commands for which we will be training our speech recognition model. These audio clips are stored in eight folders corresponding to each speech command: no, yes, down, go, left, up, right, and stop.

Remove unnecessary files:
Let us plot a bar graph to understand the number of recordings for each of the eight voice commands:

As we can see, we have almost the same number of recordings for each command.
Step 4: Preprocessing
Let us define these preprocessing steps in the code snippet below:
Convert the output labels to integer encoded labels and then to a one-hot vector since it is a multi-classification problem. Then reshape the 2D array to 3D since the input to the conv1d must be a 3D array:
Step 5: Training
Train test split - train test split is a model validation procedure that allows you to simulate how a model would perform on new/unseen data. We are doing an 80:20 split of data for training and testing.
Create a model and compile it. Now, we define a model:
Define callbacks:
Start the training:
Plot the training loss vs validation loss:
Step 6: Testing and Prediction
Now, we have a trained model. We need to load it and use it to predict our commands.
Load the model for prediction:
Start predicting:
You can always create your own dataset with creative ways like clap sounds and whistles or your own custom words and train your model to recognize them.
Demo Video
Let us now check out the demo video for this experiment.
Parting Thoughts
We just completed a tutorial on building a speech recognition system! Here is a quick recap:
We began by exploring the dataset, giving us a good feel for what is inside. Then, we prepped the data, converting it into a format suitable for training. After a train-test split, we designed a Conv1D neural network for the task.
By following these steps, we have laid the foundation for a speech recognition system. With further tweaks and your own data, you can expand its capabilities. Keep exploring the world of speech recognition!
Subscribe to Our Newsletter
Subscribe to RSS
Press & Media Hub RSS FeedRelated Articles.
More from the engineering frontline.
Dive deep into our research and insights on design, development, and the impact of various trends to businesses.

Jul 28, 2026
How to Build Medical Device Software with AI: Compliance, Architecture, and Development Process

Jul 28, 2026
ERP and MES Integration for U.S. Pharma Manufacturers: A Roadmap to Achieve Zero-Error Production and End-to-End Traceability

Jul 22, 2026